Chapter 4 Experimental Control and Statistical Abuse
Course Note:
This chapter is under construction. Some content is hidden.
4.1 Overview

Figure 4.1: Daniel interprets Nebuchadnezzar’s Dream.
Chapter 3 started with an account of an experiment from the times of Babylonian King Nebuchadnezzar, in which Daniel proposed to feed a group with a vegetable diet whilst another group continued eating the King’s royal meat. However, Daniel did not think of everything when designing his experiment. He did not take confounding bias into account. For instance, Daniel and his friends could have been healthier than the control group. Under such supposition, their strong appearance after ten days of a vegetarian diet may have nothing to do with the diet itself. Perhaps, they would have become even stronger if they had eaten the meat from the king. As we have seen in previous examples presented in this book, confounding bias happens when a variable influences both who is chosen for the treatment group as well as the experiment outcome. These variables might be known variables or act as a lurking third variable we are not aware of. Such variables are easy to spot in causal diagrams.
The term “confounding” means “to pour, mingle, or mix together”, and Figure 4.2 illustrates why such name was chosen to denominate these situations. The true causal effect \(X -> Y\) is mixed with the spurious correlation between \(X\) and \(Y\) induced by the fork \(X <- Z -> Y\) (Pearl and Mackenzie 2018).
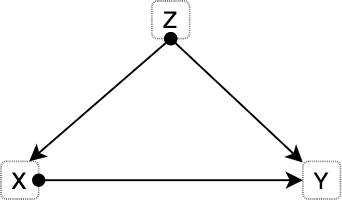
Figure 4.2: Most basic version of confounding situation: Z is a confounder of the proposed causal relationship between X and Y.
4.1.1 The smoke debate - Part II

Figure 4.3: 1946 cigarette advertisement launched by R.J. Reynolds Tobacco Company. Source: Tobacco Ads.
Many famous cases present these confounding situations. For instance, this book previously tackled the debate around smoking and lung cancer. Austin B. Hill and Richard Doll noticed that hidden biases could be present in their previous case-control studies, and the replication of the studies would not be enough to overcome them. In consequence, they began a prospective study (1951) in which they considered 60.000 physicians from United Kingdom consisting of questionnaires tackling their smoking habits. These physicians were followed over time. In just five years, heavy smokers showed a death rate from lung cancer 24 times higher than non-smokers. A similar study conducted in the United States showed that smokers died from lung cancer 29 times more often than non-smokers while heavy smokers died 90 times more frequently. However, former smokers reduced their risk by a factor of two. This behaviour is often called the “dose-response effect”, indicating that a prolonged dose of a drug causes a stronger response.
Still, R. A. Fischer and Jacob Yerushalmy remained sceptical, stating that such prospective studies failed to compare smokers to non-smokers, arguing that they were not identical groups. The rationale of the critic is that smokers in the study are self-chosen. Moreover, there might be a constitutional difference between smokers and non-smokers. For instance, smokers might be more risk-taking, or more prone to be alcoholics, which might cause adverse health effects which are then wrongly attributed to smoking by Hill and Doll studies. Another possibility they appealed to is the existence of a smoking gene that caused people to become smokers and made them more likely to develop lung cancer.
The constitutional hypothesis was almost impossible to test. In 2000, the sequencing of the human genome became real and with it the possibility to study links between genes and lung cancer. Actually, such genes do exist, as with breast cancer that make people more prone to develop certain types of cancer. In 1959, a couple of researchers published a rebuttal of Fischer’s arguments that settled the debate. One of the researchers, Cornfield, was not a statistician, nor a biologist, but instead, a historian with statistical knowledge who worked in the department of agriculture (this is of course not a cause of his family name). Cornfield aimed to debunk such constitutional hypothesis with the following reasoning: suppose the possibility of a confounding factor (e.g. smoking gene) that would fully explain the cancer risk of smokers. If smokers have 9 times the risk of developing lung cancer, the supposed confounding factor ought to be at least nine times more common in smokers to account for such risk difference. Let’s exemplify this. If 11% of non-smokers have such a gene, then 99% (since they have 9 times more risk: 11 x 9) of smokers would have to have the gene. But if 12% of non-smokers would have the smoking gene, then it is not mathematically possible for the cancer gene to fully explain the association between smoking and lung cancer. This is known as Cornfield’s inequality, and led to the development of sensitivity analysis.
The above’s explanation shows that the association between smoking and lung cancer is too strong to be explained by appeal to a smoking gene (or any other constitutional hypothesis). In essence, Cornfield’s rationale gives us a way to choose between both causal diagrams. Once it becomes evident that such constitutional hypothesis is not able to fully explain the association, the relationship between smoking and lung cancer (left diagram) becomes apparent.

Figure 4.4: The causal diagram on the left presents the situation in which the constitutional hypothesis is insufficient to explain the association between smoking and lung cancer. The diagram on the right side depicts the alternative situation in which the smoking gene fully explains the observed association.
The tobacco industry magnified any bit of controversy they could find on the scientific studies. Such organised denialism explains why the link between smoking and cancer remained so controversial in the public long after the debate was settled among epidemiologists.
Remarkably, even researchers at the tobacco companies were convinced—a fact that stayed deeply hidden until the 1990s, when litigation and whistle-blowers forced tobacco companies to release many thousands of previously secret documents. In 1953, for example, a chemist at R.J. Reynolds, Claude Teague, had written to the company’s upper management that tobacco was “an important etiologic factor in the induction of primary cancer of the lung,” nearly a word-for-word repetition of Hill and Doll’s conclusion. — The Book of Why (Pearl and Mackenzie 2018).
4.2 Experimental Control
Experimental control entails a series of procedures for experiment and observation design aimed at minimising the effects of extraneous variables (i.e. confounding factors) other than the manipulated variables (i.e. independent variable) to ensure that the measured variable (i.e. dependent variable) is only affected by the independent variables. To evaluate the effects of manipulating the independent variables, some control system is needed in which no such deliberate changes are introduced. As we have seen, sampling units (e.g. study participants) are often divided into two groups (the experimental group and the control group) in a way that the only noticeable (or significant) difference between them lies in the stimuli exerted by the experiment. Therefore, the control and experimental groups must be homogeneous in all relevant factors.
In general, there are two techniques for the formation of such homogeneous groups: individual and collective control (Bunge 2017). Individual control requires simultaneous pairing of individuals in both groups, i.e. every member of the experimental group has a corresponding equivalent member in the control group. For instance, for every thirty years old Asian man in the control group another thirty years old Asian man is assigned to the experimental group. Simultaneous pairing is complex and expensive. Statistical control has two main types. On one side, the control of distributions should be performed to equate certain parameters such as averages, spreads (i.e. std. dev.) and other collective properties (e.g. medians). This technique is more flexible as only some properties are kept under control. In this case, we would take two samples of people with the same age and height distributions. Both simultaneous pairing and distribution control share a common disadvantage regarding the formation of the groups, which could be unintentionally biased. For instance, we could assign the strongest people to the treatment (or experimental) group to make sure they bear the treatment. To prevent this issue the two groups are usually formed at random. Thanks to randomisation, all variables (including most unknown factors) that were not previously controlled become randomly distributed, minimising their effect on the dependent variables. However, randomisation is not an alternative to other techniques, but rather a complement.
4.2.1 Other experimental control techniques
There are multiple strategies for experimental control. We have previously seen the method of division into treatment and control groups. The control and treatment groups can entail two moments in time, with the initial setting being the control scenario which is later on manipulated through the intervention of certain variables (e.g. measure noise from bats in a dark chamber before and after turning a light). Another technique requires holding certain factors constant or finding scenarios (like in a field experiment) with the same background conditions. Nonetheless, constructing such conditions in a laboratory can also achieve this goal. In an elimination strategy some factors are removed to simplify study conditions, such as air resistance in a vacuum chamber or drop tower, radio waves in a Faraday cage, or gravity in space experiments. A common case of elimination is blinding, where subjects do not know which group they are assigned to (single blinding). Moreover, double-blinding implies hiding this information from the experimenter and/or the data analyst. Finally, we can separate factors by measuring their effect and correcting for it. For example, the measurements of time dilation require taking into account the Doppler effect caused by the changing distance between the observer and the moving clock. GPS systems perform adjustments due to the effects of time dilation and gravitational frequency shifts. Another example, missile trajectories are often adjusted for the effect of Coriolis force.
{kind=link}
4.3 Randomised Control Trials
The fundamental problem of causal inference tell us that it is impossible, by definition, to observe the effect of more than one treatment on a subject over a specific time period. A study participant cannot both take the pill and not take the pill at the same time. Directly observing causal effects is impossible. Nonetheless, this does not make causal inference impossible. There are certain techniques and assumptions that allow to circumvent the fundamental problem. In this context, randomized experiments allow for the estimation of population-level causal effects.
Randomisation offers a systematic solution for the division of participants (or sampling units) into two groups. In particular, RCTs are frequently regarded as a gold standard for clinical trials and among the highest quality evidence available (see Figure 4.5). However, as with every method, it will only yield fruitful results if applied correctly, and its sole employment does not warrant against other errors.
There are different types of randomisation. In simple randomisation, subjects are assigned into two groups purely randomly but in small samples, we risk creating uneven groups. Block randomisation works by randomising participants within blocks such that an equal number are assigned to each treatment. For example, given a block size of 4, there are 6 possible ways to equally assign participants to a block (AABB, ABAB, ABBA, BAAB, BABA, BBAA). Allocation proceeds by randomly selecting one of the orderings and assigning the next block of participants to study groups according to the specified sequence. A major disadvantage of this method is that it might be possible to predict the next sequence. Stratified randomisation is crucial whenever all other properties (except for the factors of interest) need to be assigned equally. The study population is first stratified into subgroups (i.e. stratas) sharing attributes, then followed by simple or block random sampling from the subgroups.
One of the main advantages of RCTs is the reduction of selection bias or allocation bias. In Chapter 4 we will see biases in more detail. The randomisation process reduces mistrust towards a potential rigged distribution of the participants. Another common advantage is that it facilitates blinding the groups from investigators and participants.
Terminology Note:
Very often terms are used interchangeably in many domain but they can also mean different things depending on the are.
By “allocation bias” we understand the bias caused by allocating patients with better prognosis to either the experimental or the control group. In the context of a randomized trial the term “selection bias” is sometimes used instead of allocation bias to indicate selection of patients into treatment arms. We avoid the term “selection bias” as it has a different meaning in epidemiology more broadly: selection of non-representative persons into a study. — (Paludan-Müller, Laursen, and Hróbjartsson 2016)
However, RCTs do not necessarily ensure that background factors are equally distributed in the treatment and control groups. For small samples randomisation can provide unequal distributions. The average number after rolling a dice an infinite amount of times will converge to 3.5, but we should not be surprised if we roll a dice 10 or 20 times obtaining considerably more occurrences of the number 6 than the other numbers. The danger of relying on pure randomisation to balance covariates has been described in (Krause and Howard 2003) (Morgan and Rubin 2012). For this reason is essential to check for imbalances in known factors after randomisation. Stratified randomisation also helps balancing known factors. Nonetheless, randomisation does not necessarily guarantee full control of unknown factors but on average their effect should be significantly smaller than the treatment applied (Deaton and Cartwright 2018).
When we use an RCT to evaluate an intervention, we do so with respect to one or more endpoints (or outcomes) that will be measured in the future, after the period of intervention. It could be blood pressure, death, quality of life, etc. We want to understand the causal effect of the intervention on that outcome, but this is tricky. That’s because to really understand the effect of the intervention, we would need to give it to someone and measure the outcome to see what happened. Then we would need to reset the universe back to the exact point when the intervention was given, withhold it this time, and see what happened when they were left untreated. The difference in the outcomes between the two scenarios would be our estimate of the causal effect of the intervention. This is clearly a fantasy, but hope is not lost. Thankfully we can mimic this counterfactual situation by randomizing people into groups, and since we are now talking about groups, we have to start talking about distributions of future outcomes. — Darren Dahly, PhD
Although RCTs are still preferred to observational studies, there are scenarios in which intervention is not possible. For instance, we cannot assign participants to be obese or not in order to study the effect of obesity on heart diseases.

4.3.1 Origins of RCTs
R.A. Fisher (1890-1962) conceived the RCTs in the 1930s for its employment in agriculture experiments. Fisher designed intricate approaches to disentangle the effects of fertiliser from other variables. Using the Latin Square, he would divide the field into a grid of subplots to test each fertiliser with each combination of soil type and plant. However, in this scenario the experimenter would observe the effects of the fertiliser mixed (i.e. confounded) with a variety of other things (e.g. soil fertility, drainage, microflora). Fischer realised that the only design that would “trick nature” is one where the fertilisers are assigned randomly to the subplots. Of course, sometimes you might be unlucky and assign a certain fertiliser to the least fertile subplots, but other times you might get the opposite assignment. A new random allocation is generated each time the experiment is conducted. By running the experiment multiple times the luck of each allocation is averaged.
But Fisher realized that an uncertain answer to the right question is much better than a highly certain answer to the wrong question. […] If you ask the right question, getting an answer that is occasionally wrong is much less of a problem. You can still estimate the amount of uncertainty in your answer, because the uncertainty comes from the randomization procedure (which is known) rather than the characteristics of the soil (which are unknown). — Section “Why RCTs work” in Chapter 4 from (Pearl and Mackenzie 2018)
The Book of Why describes the aforementioned experiment in causal terms (Pearl and Mackenzie 2018). The causal diagram from Figure 4.6 depicts a model describing how the yield of each plot is determined by both the fertiliser and other variables, but the effect of the fertiliser is also affected by the same variables (red arrows). The experimenter aims to know about the effect of the fertiliser controlling for the latter effects. In other words, a model in which the effects represented by the red arrows are controlled. In this second scenario, the relation between Fertilizer and Yield is unconfounded since there is no common cause of Fertiliser and Yield.
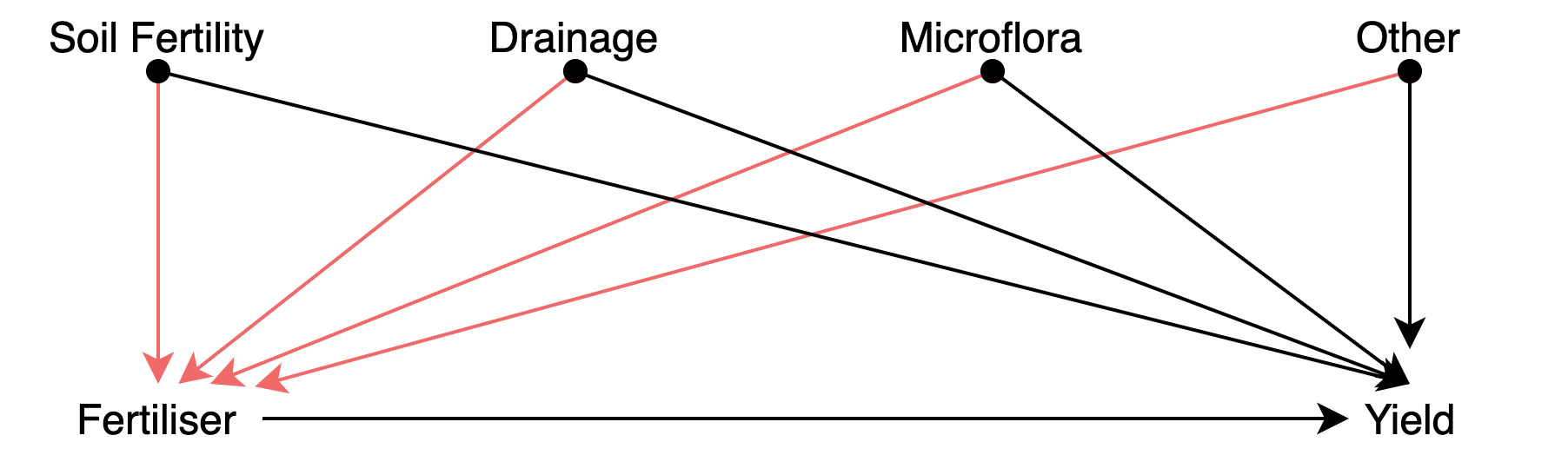
Figure 4.6: Causal diagram depicting an improperly controlled experiment.
4.3.2 Validity
When a hypothesis is designed to explain certain observed phenomena, it will of course be so constructed that it implies their occurrence; hence, the fact to be explained will then constitute confirmatory evidence for it. But it is highly desirable for a scientific hypothesis to be confirmed also by “new” evidence — by facts that were not known or not taken into account when the hypothesis was formulated. Many hypotheses and theories in natural science have indeed received support from such “new” phenomena, with the result that their confirmation was considerably strengthened. — (Hempel 1966)
Transferring RCTs results to other scenarios is not trivial. All in all, RCTs results concern a particular sample used during the study. The study sample is of course drawn from a larger group, i.e. the population, but the RCT results cannot be simply applied to another sample drawn from the population. Randomisation is not the same as random sampling from the population. In fact, there are many RCT studies that misrepresented certain population groups. An example of women inclusion issues in clinical studies includes the under-representation of women in stroke randomized controlled trials, which leads to misleading conclusions that affect stroke care delivery (Tsivgoulis, Katsanos, and Caso 2017). A similar bias exists in animal research, including lab mice.
Most rodents used in biomedical studies — the ones that suss out the effects of treatments before they make it to humans — have boy parts and boy biological functions. And that particular kind of gender imbalance has cascading effects. A growing body of evidence indicates that females process pain differently than males. But many lab scientists who study ways of treating pain still use all-male cohorts of lab mice. They say it’s because male mice and rats aren’t as hormonal as females—because isn’t that what they always say—and are therefore more reliable in terms of getting data. And that means the scientific community is ignoring research that might help women manage pain better. — Science Has a Huge Diversity Problem… in Lab Mice - Wired
Of 2,347 articles reviewed, 618 included animals and/or cells. For animal research, 22% of the publications did not specify the sex of the animals. Of the reports that did specify the sex, 80% of publications included only males, 17% only females, and 3% both sexes. A greater disparity existed in the number of animals studied: 16,152 (84%) male and 3,173 (16%) female. — (Yoon et al. 2014)
Therefore, RCTs must be internally valid, — i.e. the design must eliminate the possibility of bias — but to be clinically useful the result must also be relevant to a well-defined group of patients in a particular clinical setting (i.e. external validity). Differences between trial protocol and routine practice also affect the external validity of RCTs. In (Rothwell 2006), the authors list some of the most important potential determinants of external validity.
4.4 Cross-validation in Machine Learning
As data scientists, you may wonder why the previous practices are relevant to your job. In this section I want to show how similar control measures must be considered regarding machine learning (ML). When applying supervised ML methods, is important to prevent over-fitting and under-fitting situations. In particular, over-fitting occurs when a model begins to memorize training data rather than learning to generalize from a trend (see Figure 4.7). One of the techniques to detect or lessen the effect of over-fitting includes cross-validation. The basis of this technique is to test the generalization power of the model by evaluating its performance on a set of data not used during the training stage.
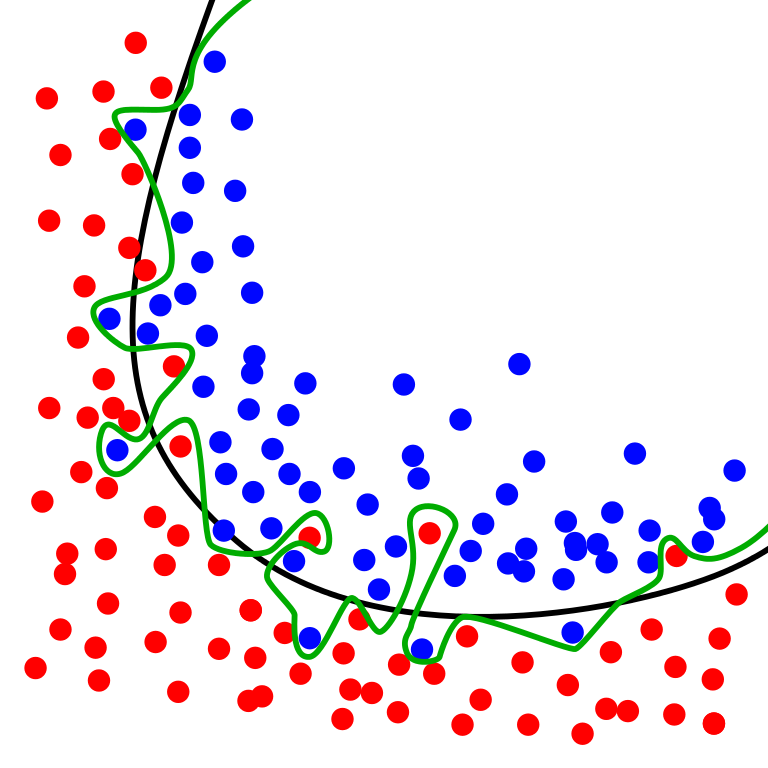
Figure 4.7: Source: Wikimedia. The green line represents an overfitted model and the black line represents a regularized model. While the green line best follows the training data, it is too dependent on that data and it is likely to have a higher error rate on new unseen data, compared to the black line.
{kind=link}
The simplest approach is the hold out method which entails spliting the dataset into a train and test sets. However, yet another part of the dataset is often held out (validation set) so that the model training proceeds on the training set, the model evaluation on the validation set, and once the hyperparameters are successfully tweaked, the final evaluation is conducted on the test set. This process reduces the amount of data available for training. Cross-validation (CV) alleviates this issue.
The following procedure (see Figure 4.8) is followed for each of the \(k\) “folds”:
- A model is trained using \(k-1\) of the folds as training data.
- The resulting model is validated on the remaining part of the data.
The performance measure reported by K-fold CV is then the average of the values computed in the loop. This approach can be computationally expensive, but does not waste too much data (Pedregosa et al. 2011).
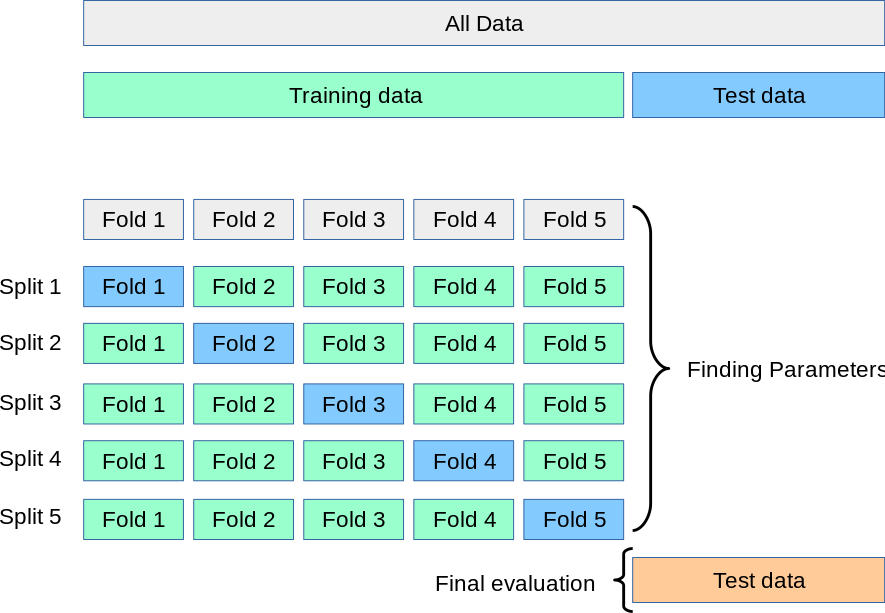
Figure 4.8: Source: Scikit-Learn. A test set should still be held out for final evaluation, but the validation set is no longer needed when doing CV. In the basic approach, called K-fold CV, the training set is split into k smaller sets (Pedregosa et al. 2011).
However, the vanilla approach to K-fold CV does not consider certain properties of the dataset. In particular, K-fold CV is not affected by classes or groups. For instance, the training set of the first CV iteration in Figure 4.9 does not contain one of the classes.
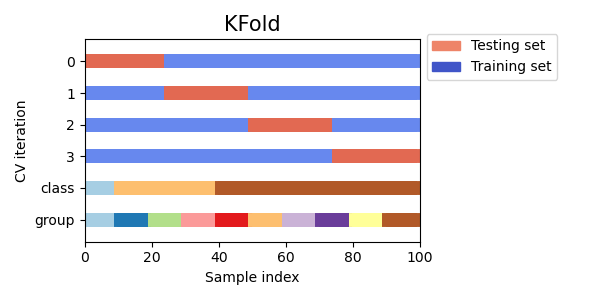
Figure 4.9: Source: Scikit-Learn. K-fold CV is not affected by classes or groups.
Issues similar to the ones previously studied regarding RCTs can arise when conducting cross-validation. Some problems exhibit a large imbalance in the distribution of the target classes. For example, the negative class can be more representative than the positive class. In such cases, stratified sampling is recommended (see Figure 4.10) to preserve relative class frequencies in each train and validation fold.
One strong assumption of machine learning theory is that data is Independent and Identically Distributed (i.i.d.), i.e. that all samples stem from the same generative process and that such process is assumed to have no memory regarding past samples. For example, a succession of throws of a fair coin is i.i.d. since the coin has no memory, so all the throws are independent. In this sense, if we know that the generative process has a group structure (e.g. samples collected from different subjects, experiments, measurement devices) we should use group-wise CV. The grouping of data depends on the context. For instance, in medical data, we can find multiple samples for each patient, so it makes sense to group the samples by patient to prevent any data leakage. Similarly, problems where the samples have been generated using a time-dependent process call for time-series aware CV schemes.
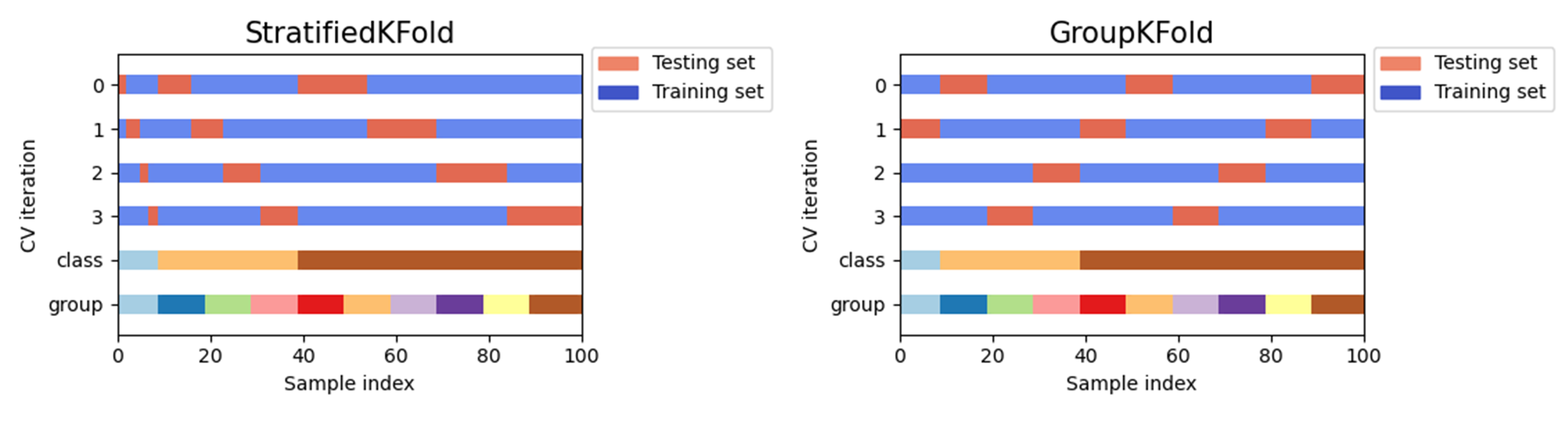
Figure 4.10: Source: Scikit-Learn. Other K-fold CV strategies. GroupKFold is a variation of K-fold which ensures that the same group is not represented in both testing and training sets. StratifiedKFold is a variation of K-fold which returns stratified folds: each set contains approximately the same percentage of samples of each target class as the complete set.
Similar to RTC internal validity, cross-validation does not ensure transferability to other scenarios. External validation must be performed with independent datasets to ensure robustness against new scenarios. Consider a deep-learning algorithm trained to predict the number of years a patient will survive based on its characteristics and the medication administrated. This system could be then transferred to a different hospital, in another country, region, or city where the population characteristics (diet, hygiene, professions) are different. The model will require undertaking a certain recalibration process to learn the new conditions.
4.5 Surrogates, Proxies, Confounders and Colliders
In this section we address certain induced biases that may affect many data scientist tasks, including data analysis and machine learning solutions. Induced biases often arise during the design and data collection process, but they can also arise during the data analysis step.
4.5.1 Surrogates and Proxies
During this course we may have seen the term surrogate and proxy many times in the context of particular examples. These terms can be used interchangeably. In general, surrogates and proxies are variables that can be measured and employed in place of some other variable that cannot be measured. This impediment may be related to legal, ethical restrictions or technical difficulties. Of course, the employment of such surrogate metric or variable depends upon the assumption that such relationship with the true variable holds for our purposes. For instance, it may not hold for the general population and just for the acquired sample, therefore this surrogate may present external validity issues.
The employment of surrogate metrics may seem attractive for certain purposes but is a source of problems when they are inadvertently exploited in machine learning solutions, algorithms or any other modelling approach.
For instance, the ZIP code is a widely accepted proxy that can often reveal race, ethnicity, or age. From an ethical point of view, such proxies can be employed for the good or the bad. In the United States of America, it is forbidden by law from considering race in admissions. However, consider that a campus may want to ensure certain diversity or lack of it. In Texas, the “Top 10 Percent Law” is the common name for the state law passed in 1997 that guarantees Texas students who graduated in the top ten percent of their high school class automatic admission to all state-funded universities. The goal was to find a way to increase the enrollment of black and Latino students after a federal court banned race-based affirmative action in the state. Without entering into the fairness and impact of the law, which is still open to debate, it is clear that in scenarios where most high schools have a majority of a certain race, such a race will be favoured over the rest. Therefore, such rules may have a racial or discriminatory impact on university admissions. However, in this case, there may be other factors in place, since being granted access does not mean that you can, for instance, assume the costs of university tuition and so on.
Similarly, say lenders would like to exclude borrowers of certain race. Despite the law prohibiting from doing this, the lenders could find a proxy or surrogate such as neighborhood to continue excluding by race by benefiting from knowing that certain districts or areas are populated by racialised citizens.
Importantly, should the underlying association change, the proxy or surragate would have to be re-calibrated.
4.5.2 Confounding factors
Related to this, we can find confounding variables. Confounders (see age in Fig. 4.11) are variables that affect both the potential predictor variable (physical activity) and the outcome (cardiac problems). When the presence of confounders is unknown and in lack of experiments specifically designed to minimise them (e.g., randomised controlled trials), we cannot control for them. Uncontrolled confounders may lead to wrongly conclude that a given feature is a strong predictor of the outcome when in reality the association is spurious.
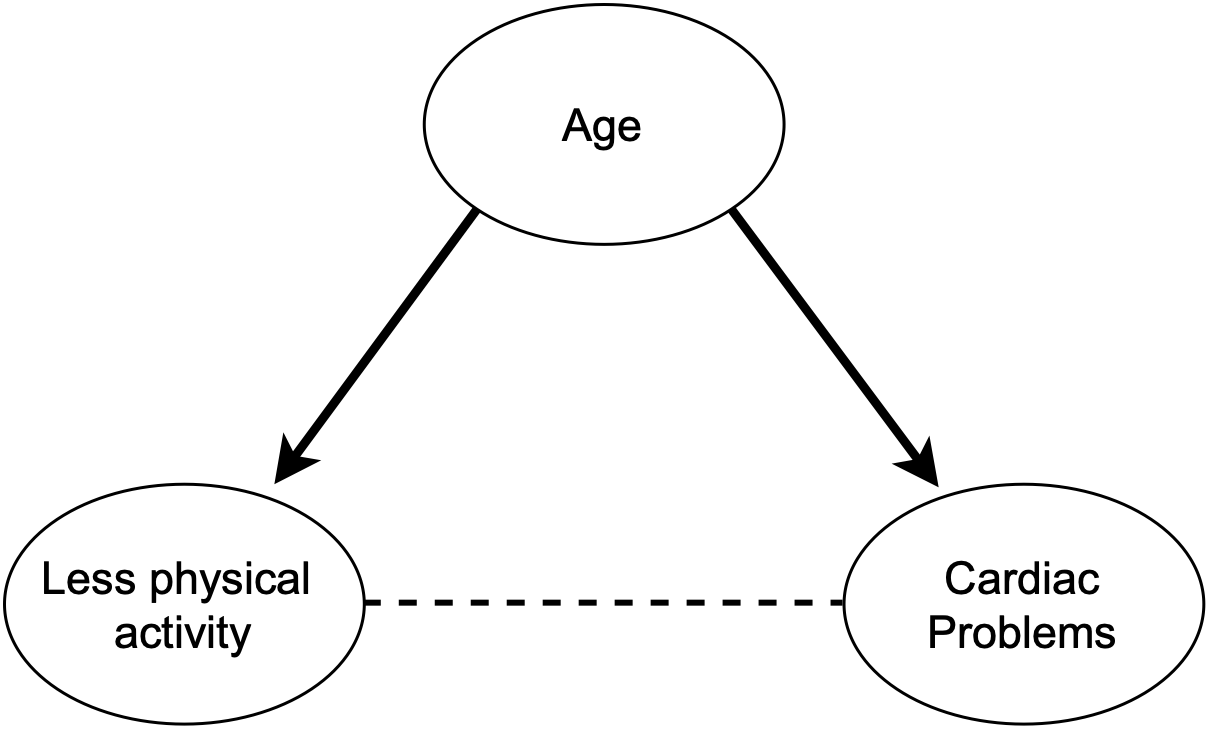
Figure 4.11: DAG depicting a scenario with a confounding factor (age) acting (solid lines) in both the predictor and outcome (relationship depicted with a dashed line).
Importantly, such associations may not hold anymore when the sample comes from a different setting where the confounder is differently expressed, e.g. income level may play a different role on diabetes treatment depending on the country. In the context of machine learning, when a model learns spurious associations between predictors and outcomes, an undetected overfitted model is produced, resulting in poor generalisation capabilities that eventually unveil during its translation into real-world settings (Garcia, Vega, and Hertel 2022).
4.5.3 Collider bias and M-bias
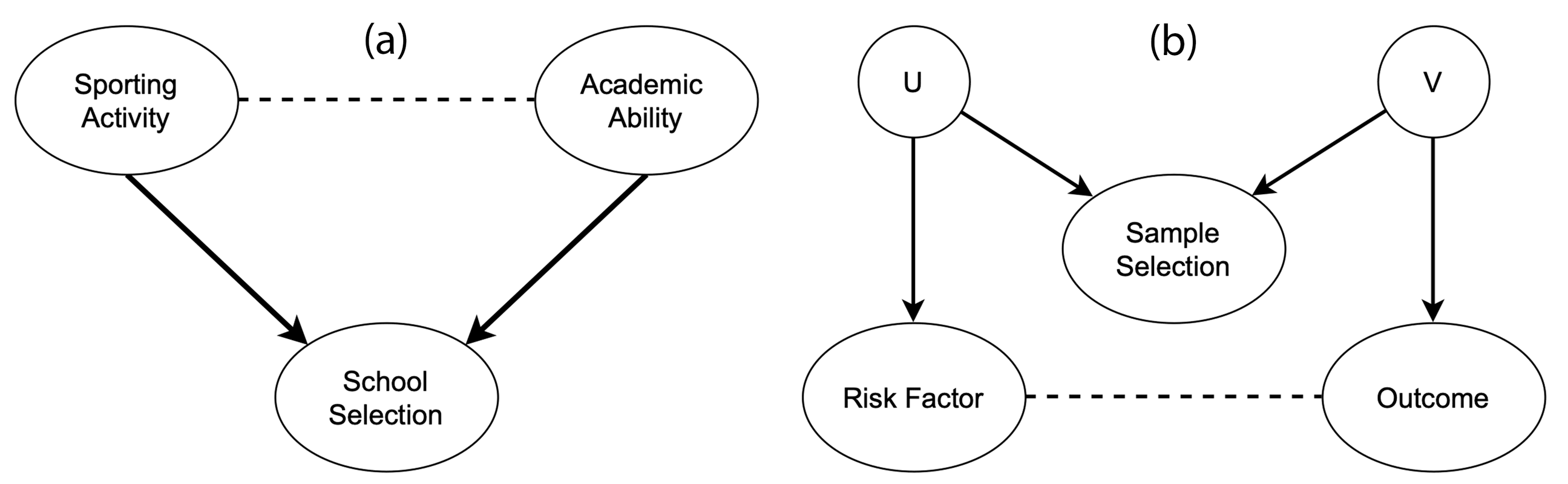
Figure 4.12: Directed arrows indicate causal effects and dotted lines indicate induced associations. (a) shows a scenario in which collider bias could distort the estimate of the causal effect of sporting activity on the academic ability. As shown in (b), the relation between the two associated variables can be indirect, with the risk factor and the outcome being indirectly associated with sample selection through unmeasured confounding variables (U and V).
A collider entails a variable that is influenced by two other variables, i.e. collider bias occurs when an exposure and outcome (or factors causing these) each influence a common third variable. The associations induced by collider bias are properties of the sample, rather than the individuals that comprise such a sample. Thus, such associations fail to generalise beyond the sample and may be inaccurate even within the sample, threatening validity (Garcia, Vega, and Hertel 2022). Figure 4.12 (a) shows how academic and sporting abilities can influence selection into a prestigious school. These two factors are barely correlated in the general population, but they become strongly correlated in the sample because the school enrolment depends on them (see Figure 4.13). Figure 4.12 (b) shows that the association of interest can be distorted without their variables being directly influencing the collider. Factors affecting the sample selection can themselves influence the variables of interest, distorting the relationship between them (Griffith et al. 2020). This effect is known as M-bias.
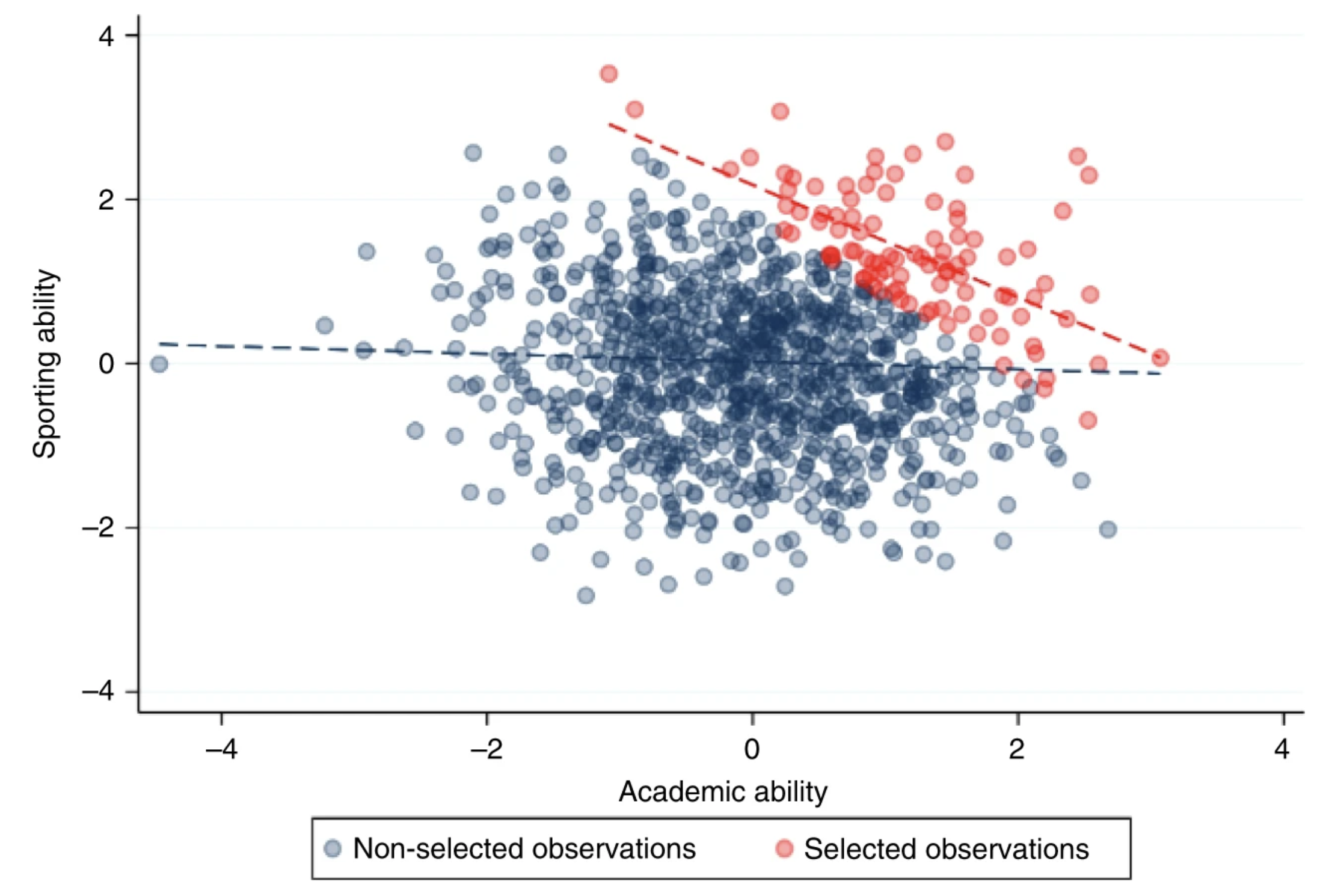
Figure 4.13: These traits are negligibly correlated in the general population (blue), but because they are selected for enrolment they become strongly correlated when analysing only the selected individuals (red). Extracted from (Griffith et al. 2020).
“If we assume that a given covariate influences both the hypothesised risk factor and the outcome (a confounder), it is appropriate to condition on that covariate to remove bias induced by the confounding structure. However, if the covariate is a consequence of either or both the exposure and the outcome (a collider), rather than a common cause (a confounder), then conditioning on the covariate can induce, rather than reduce bias. That is, collider bias can also be introduced when making statistical adjustments for variables that lie on the causal pathway between risk factor and outcome. A priori knowledge of the underlying causal structure of variables and whether they function as a common cause or common consequence of risk factor and outcome in the data generating process can be hard to infer. Therefore, it is appropriate to treat collider bias with a similar level of caution to confounding bias.” — (Griffith et al. 2020)
Note for data scientists!
Covariate: An independent variable that can influence the outcome of a given statistical trial, but which is not of direct interest. A covariate is a continuous variable that is expected to change (“vary”) with (“co”) the outcome variable of a study.
4.6 Data alone is not enough
The confirmation of a hypothesis is often considered to increase as the number of favourable test findings grows, but the increase in confirmation, produced by one new favourable instance, will generally become smaller as the number of previously established favourable instances grows (Hempel 1966). Many researchers and data scientists blindly rely on the dogma the more data, the merrier but the addition of one more favourable finding raises the hypothesis confirmation but little. The confirmation of a hypothesis depends not only on the quantity of the favourable evidence available but also on its variety.
As we have seen during this course, data alone is not enough. Note that this is especially a problem for solutions based on Machine Learning, since domain knowledge or context should be introduced somehow to direct the model in the desired direction.
“There is no learning without bias, there is no learning without knowledge” — (Skansi 2020) (Domingos 2015).
A relevant example on how data depends on its context is user ratings or opinions. For instance, the meaning of fashionable clothes changes over time, as do political terms. This issue is known as concept drift (Kubat 2017). Similarly, a text-mining engine to tag biology terms with the corresponding ontology terms may confuse elements between species, as several entities appear in multiple animals or organisms. Context is crucial for external validation and translation of solutions into real-world settings. A system for clothes recommendation should adapt to countries, cultures or ages. Similarly, a health system to predict patient risk based on disease comorbidities must be calibrated for each country or region (e.g. Diabetes treatment is often affordable in the EU, but an expensive treatment in the USA, which increases its mortality rate).
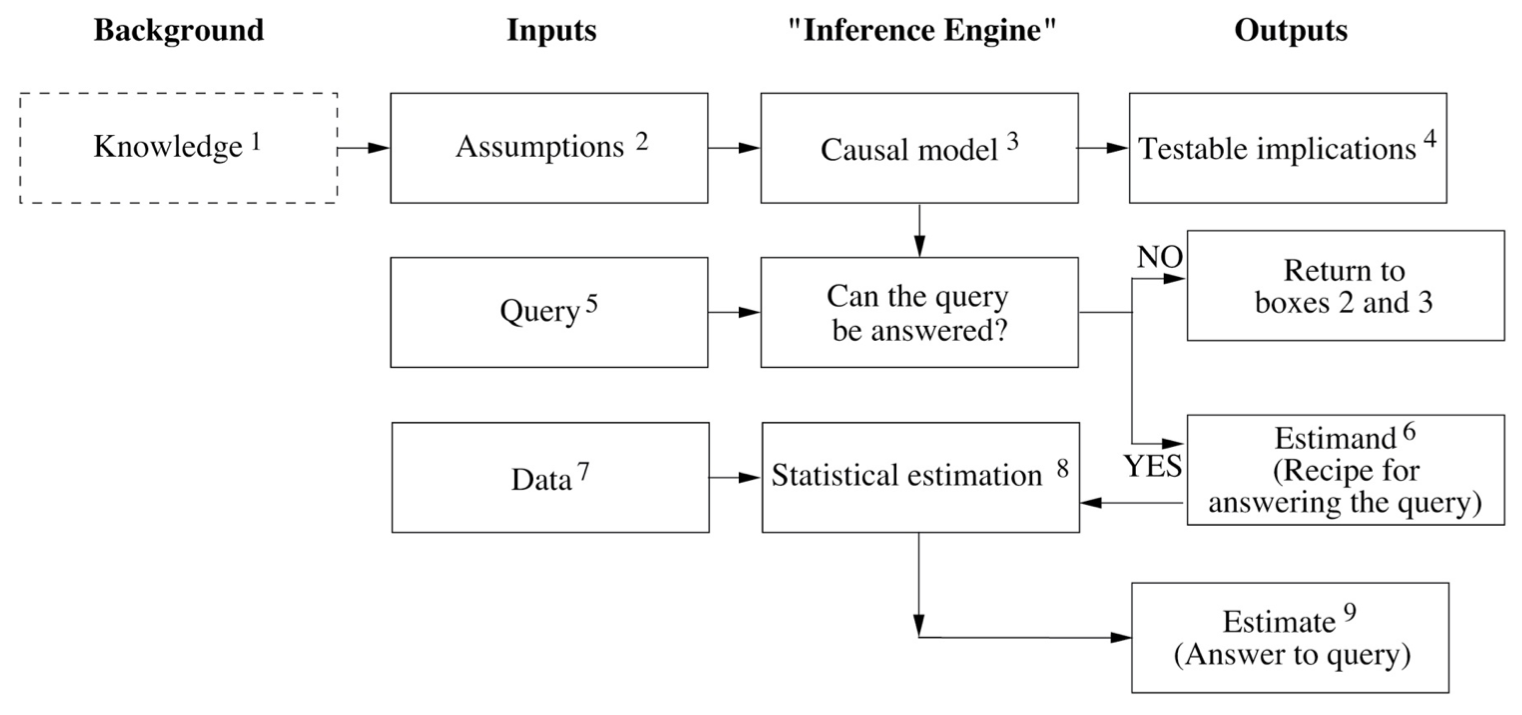
Figure 4.14: Diagram extracted from The Book of Why. The diagram depicts a hypothetical inference engine that combines data and causal knowledge to produce answers to questions of interest. Knowledge (dashed) is not part of the engine but required for its construction. Boxes 4 (testable implications) and 9 (estimate) could also feedback such knowledge to incrementally improve the engine.
Figure 4.14 represents an ideal causal inference engine for scientific questions. Today, causal models for scientific applications are based on a similar design. It is important to notice how this diagram showcases the importance of extra-observational information (i.e. information other than data) such as assumptions, which derive from the available knowledge. With them, a causal model is built in any of its different forms, e.g. logical statements, structural equations, causal diagrams, etc. Causation (or a causation assumption) can be defined from the following analogy, \(X\) is a cause of \(Y\) if \(Y\) listens to \(X\) and determines its value in response to what it hears. For instance, the patient’s lifespan \(L\) is determined by the intake of drug \(D\). In this case, \(D\) acts as a cause of \(L\) (although it might not be the only cause), which is represented by an arrow from \(D\) to \(L\) in a causal diagram (see Figure 4.15). For the sake of simplicity the other causes of \(L\) can be grouped in an additional variable \(Z\).
In box \(4\) the patterns encoded in the paths of the causal model yield a series of observable consequences (or data dependencies), that we know as testable implications (remember the hypothetico-deductive method?). These implications can be used to test the model. For instance, the lack of path between \(D\) and \(L\) would imply that \(D\) and \(L\) are independent, meaning that a variation of \(D\) will not alter \(L\). If such implication is contradicted by the data, the model should be revised bearing in mind this new knowledge. The box \(5\) is in charge of the scientific query which must be encoded in causal vocabulary, e.g. \(P(L | do(D))\), i.e. what is the probability that a typical patient would live \(L\) years given that it takes the drug \(D\)?.
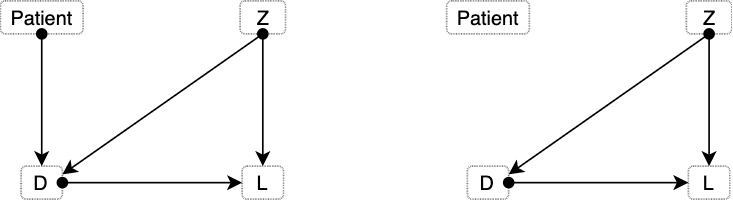
Figure 4.15: Diagram depicting two different scenarios: before, and after an intervention.
The \(do()\) operator represents an intervention in the system, in contrast to an observation \(P(L|D)\). An instance of the latter would entail letting the patient decide between taking or not the drug (see left side of Figure 4.15). Such decision might be affected by other variables we are not aware, like the patient’s education, family, etc. However, when we make an intervention and assume that we are giving the drug to the patient, the arrow illustrating the patient’s decision disappears (right side of Figure 4.15).
The estimand is the recipe to answer the scientific query, written as a probability formula, such as \(P(L | D, Z) \times P(Z)\). Once the data is introduced, an estimate can be calculated. Importantly, some queries may not be answerable regardless of the amount of data collected. For instance, our causal model could indicate that both \(D\) and \(L\) depend upon a third variable \(Z\). If there would not be any way to measure \(Z\), the query \(P(L | do(D))\) would be unanswerable. Collecting data for this question would be worthless. Under such a scenario, the causal model needs to be reviewed. Either to introduce new knowledge to enable estimating \(Z\), or to simplify the previous assumptions, potentially increasing the risk of wrong answers, e.g. stating that \(Z\) has a negligible effect on \(D\).
Following the analogy, the data acts as the ingredients of the recipe provided by the estimand. Our estimate (box \(9\)) represents an approximate answer to the query. Such an answer is approximate because data always represents a finite sample from a theoretically infinite population (Pearl and Mackenzie 2018). An example of answer in this case could be that drug \(D\) increases lifespan \(L\) of diabetic patients by \(30\% \pm 10\%\).
The most important fact about the diagram in Figure 4.14 is that data and causal model are two independent pieces of the puzzle that later work together. Data is collected after the causal model and stating that the scientific query can be answered. The estimand computation does not require any data. Comparing this to conventional machine learning (ML) systems, a ML solution would have to be re-trained when moved from one hospital to another since such model just fitted a function to data, without levering from any causal model.
4.7 Examples
4.7.1 Covid-19: How can efficacy versus severe disease be strong when 60% of hospitalized are vaccinated?
There are three kinds of lies: Lies, damned lies, and statistics
In this blog post, biostatistics Professor Jeffrey Morris demonstrates how without properly controlling for age, efficacy against severe disease in Israel may appear weak when in fact within each age-group it is extremely strong. Consider the table from Figure 4.16 and the following data from the the Israeli government. As of August 15, 2021 nearly 60% of all patients currently hospitalized for COVID-19 are vaccinated. Out of 515 patients currently hospitalized with severe cases in Israel, 301 (58.4%) of these cases were fully vaccinated.
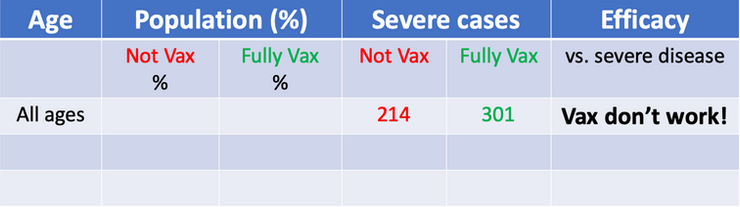
Figure 4.16: Misleading table. This kind of tables have been used to claim that vaccines do not work or that its efectiveness reduces over time.
The numbers are true, but we need more than that to draw a proper conclusion about vaccine efficacy. Consider the following extreme scenarios. If the number of vaccinated people would be 0 we would expect all severe cases to be not vaccinated (obviously). On the other hand, if 100% of people would have been vaccinated, we would expect all severe cases to proceed from vaccinated people and 0 from non vaccinated. In this case, we have an in-between situation where 80% of residents (older than 12 years) have been vaccinated. Therefore, since the group of vaccinated people is larger than the non-vaccinated, we can expect more severe cases in absolute numbers. However, once we adjust for vaccination rates and normalise the counts, the story changes. The rate of severe cases is three times higher in unvaccinated individuals.
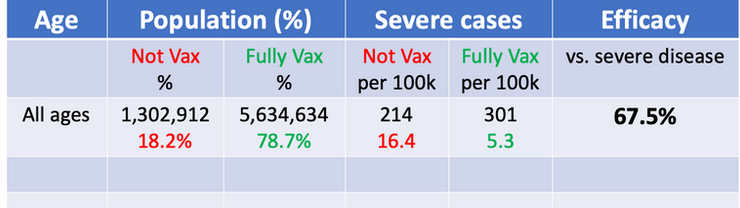
Figure 4.17: Table adjusted for vaccination rates.
Vaccine Efficacy vs. Severe disease = 1 - 5.3/16.4 = 67.5%. The interpretation of this number is that the vaccines are preventing >2/3 of the serious infections leading to hospitalization that would have occurred sans vaccination.
Still, the obtained efficacy is lower than what we would expect. There are other factors that contribute to this confusion, including: age disparity in vaccinations, old people is more likely to be hospitalized than young people, etc.
I recommend going through the blog post to see how the author continues to apply adjustments and stratifications to find the true efficacy of the vaccines. Moreover, this is a good example of the Simpson’s paradox, where misleading results can be obtained in the presence of confounding factors.
In conclusion, as long as there is a major age disparity in vaccination rates, with older individuals being more highly vaccinated, then the fact that older people have an inherently higher risk of hospitalization when infected with a respiratory virus means that it is always important to stratify results by age; Even more fundamentally, it is important to use infection and disease rates (per 100k, e.g.) and not raw counts to compare unvaccinated and vaccinated groups to adjust for the proportion vaccinated. Use of raw counts exaggerates the vaccine efficacy when vaccinated proportion is low and attenuates the vaccine efficacy when, like in Israel, vaccines proportions are high.
4.7.2 Misinterpretations of hurricane forecast maps
The following article by Alberto Cairo published in The New York Times explains how hurricane cone forecast maps can mislead the public and produce real-world consequences.
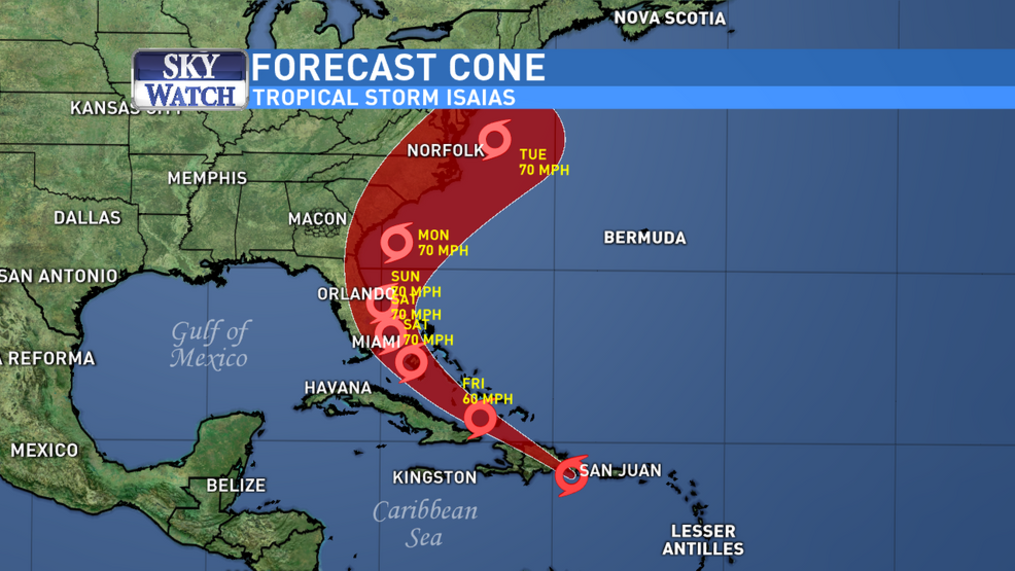
Figure 4.18: Example of hurricane forecast cone graphic in TV.
Studies show that people can misinterpret this type of map as indicating that the hurricane will get bigger over time. Others think it shows areas under threat. Recent research suggests that 40% of people would not feel threatened if they lived just outside of the cone. Moreover, people who live inside the cone, but far from the center, take less precautions than those closer to the central line. These misunderstandings have real-world consequences. Actually, the cone represents a range of possible positions and paths for the storm’s center. The dots in the middle of the cone correspond to the forecast of where the hurricane’s center could be in the following five days. But there’s a good chance that the actual center of the storm will not end up being at those positions.
To create the cone, the National Hurricane Center (N.H.C.) surrounds each estimated position of the storm center with circles of increasing size. These circles represent uncertainty, meaning that the storm center may end up being anywhere inside the circles — or even outside of them. The uncertainty circles grow over time because it is more difficult to to predict what will happen in five days from now than in one day. Finally, a curve connects the circles, resulting in what is popularly known as the ‘cone of uncertainty’.
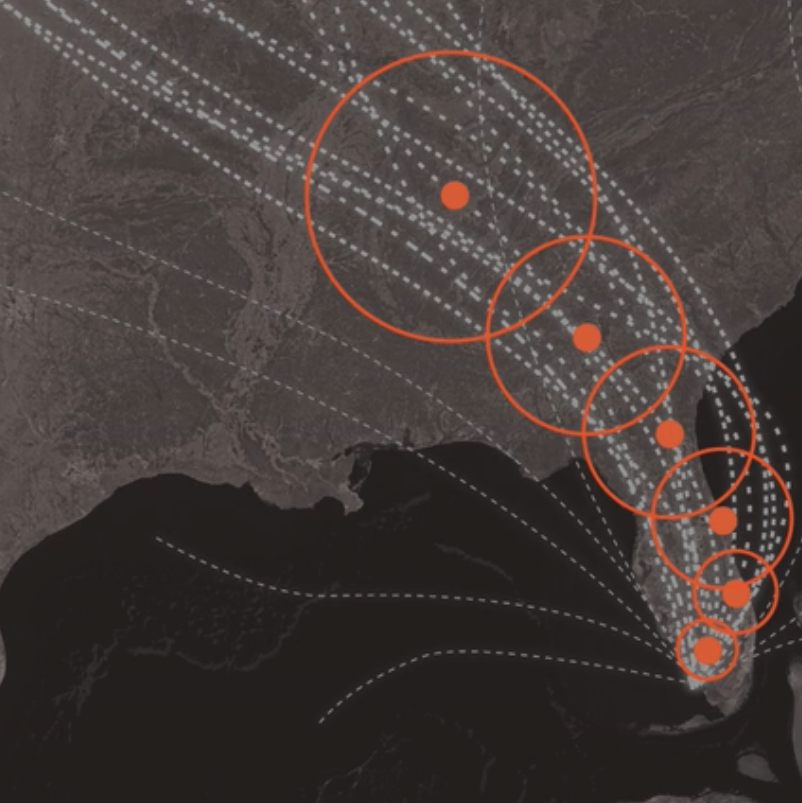
Figure 4.19: Cone of uncertainty.
N.H.C. says cones will contain the path of the storm center only 60 to 70 % of the time. In other words, one out of three times we experience a storm like this, its center will be outside the boundaries of the cone. Hurricanes are also hundreds of miles wide, and the cone shows only the possible path of the storm’s center. Heavy rain, storm surges, flooding, wind and other hazards may affect areas outside the cone. The cone, when presented on its own, doesn’t give us much information about a hurricane’s dangers. The N.H.C. designs other graphics, including this one showing areas that may be affected by strong winds. But these don’t receive nearly as much attention as the cone. The cone graphic is deceptively simple. That becomes a liability if people believe they’re out of harm’s way when they aren’t. As with many charts, it’s risky to assume we can interpret a hurricane map correctly with just a glance. Graphics like these need to be read closely and carefully. Only then can we grasp what they’re really saying.
From a NYT article by Alberto Cairo
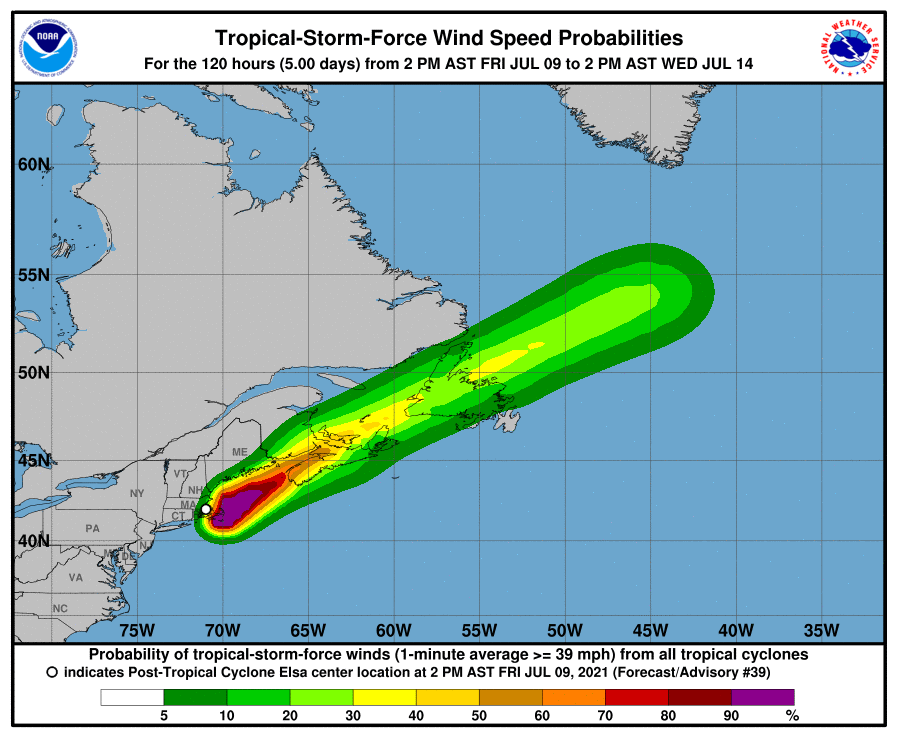
Figure 4.20: Other graphics designed by USA National Hurricane Center.