Chapter 1 Scientific Goals, Methods and Knowledge

Figure 1.1: Allegory of the cave from the Greek philosopher Plato. Source: Wikimedia user 4edges.
{kind=link}
To gain knowledge about the world, the universe, and the rules behind the phenomena that shape them, we often require taking measurements about the entities we seek to understand. We can indeed play with many of them: we can take a rock and throw it, we can dissect a mouse or mix multiple liquids. However, to compare rocks, mice or liquids, we must take measurements that allow us to tell their differences and commonalities. This information, these data, are not the entities themselves, and when we work with them, we stop playing with the real entities. We begin to play with shadows, and two different objects can certainly project the same shadow. The relationships showcased by these entities are not contained in the data but in the reality they live on, of which the data is merely a blurry shadow of reality. Therefore, data science works with the shadows of real objects, and this practice involves assessing risks, identifying mistakes and avoiding situations of appearance of knowledge.
In this course, we will introduce central topics of the scientific method and translate practices employed in natural sciences to the domain of data science. Such practices are meant to control the plethora of considerations that must be bore in mind when playing with shadows. From the confirmation of hypothesis, asymmetries of explanation and causality, to the experimental control techniques and their relationship with surrogate variables, confounders and colliders.
Illustrated with examples, this course will tackle the scientific goals, the definition of knowledge, the criteria for a relevant hypothesis, the conditions for experiment success and requirements for good scientific models. Once the empirical cycle is clear, the last chapters are dedicated to experimental control, statistical abuse and data ethics. These chapters provide equivalents of techniques employed in natural sciences for their use in data science, relating experimental designs like Randomised Control Trials to causal inference or cross-validation in Machine Learning. Finally, the chapter on data ethics does not just introduce ethical frameworks but delves into how to bring such values to action.
Allegory of the cave from the Greek philosopher Plato
“Plato describes a group of people who have lived chained to the wall of a cave all their lives, facing a blank wall. The people watch shadows projected on the wall from objects passing in front of a fire behind them and give names to these shadows. The shadows are the prisoners’ reality, but are not accurate representations of the real world. The shadows represent the fragment of reality that we can normally perceive through our senses, while the objects under the sun represent the true forms of objects that we can only perceive through reason. Three higher levels exist: the natural sciences; mathematics, geometry, and deductive logic; and the theory of forms.” — Wikipedia
1.1 What is Science?
[…] questions about scientific methodology and knowledge in philosophy of science are really continuous with questions in cognitive science about how human beings reason and form beliefs. However, one need not imagine an absolute distinction between philosophy and empirical forms of inquiry to appreciate the broad differences between the latter and the study of philosophical questions that arise when we reflect on science. Of course, this characterisation is of little use unless we know what science is, so perhaps the most fundamental task for the philosophy of science is to answer the question, ‘what is science?’. — (Ladyman 2012)
This question attempts to answer what common features share subjects such as physics or biology to be called sciences, i.e. what it is that which makes something a science. The problem of saying what is scientific and what is not is called the demarcation problem. Among other things, science aims to understand, explain and predict the world we live in. But also religions, astrology or alchemy attempt to understand, explain or predict our world. What makes them different from science?
Four historical elements are essential for the development of a scientific approach. Namely: to seek explanations of natural phenomena; to argue; to investigate the rules of argumentation and logical validity; to build them into a logically consistent system. (Johansson et al. 2016)
Rather than finding a proper definition of science, which many have struggled with, we will focus on what makes science different and why its methods are called scientific.
1.1.1 Scientific Goals and Knowledge
The main goals of science include prediction, explanation, understanding, and design. Through observation we can draw explanations and achieve understanding of nature phenomena. Once we understand we can aim to make predictions. Thanks to our understanding we can as well design experiments, instruments and solutions that help us further explaining, understanding and predicting our world. Predicting \(X\) means knowing that at time t, \(X\) will happen. Explaining \(X\) means to know the cause(s) that produced \(X\). Designing \(X\) requires knowing that artifact \(X\) will satisfy certain functions \(F\). All these goals share a common ingredient, scientific knowledge. Scientists arrive to such knowledge by applying the scientific method (see § 1.2). The goals of science are achieved through a series of activities that constitute the scientific method which include systematic observation and experimentation, inductive and deductive reasoning, and the formation and testing of hypotheses and theories.
Knowledge is justified true belief — Plato (428 - 348 BC)
The most popular definition of knowledge was given by philosopher Plato in the above’s quote. This definition specifies that a statement must meet three criteria to be considered knowledge. This definition of knowledge is sufficiently good for this course. However, the definition of knowledge is an ongoing debate among epistemologists. Although these criteria are necessary conditions, they are not sufficient as there are situations that satisfy all these conditions and yet don’t constitute knowledge (see Gettier cases) but such cases are rather philosophical and will not be discussed during this course.
- True because statements must refer to an actual state of the world.
- A wet sidewalk does not necessarily imply it rained even if you believe so.
- Even if we are justified to believe that something is true, it might not be true.
- Justified because you need proper proof, evidence or reasons to defend our statement.
- Even if it actually rained, a wet sidewalk caused by a sprinkler is not good justification for you to believe it rained.
- Belief because even under justified reasons about true facts, people can choose not to believe such knowledge. We define belief as to the state of mind of a person that thinks something is the case. This state of mind is of course tied to the individual and comes in degrees. We act based on our beliefs and values, and new knowledge can affect these.
Certainty of belief and truth are different. Is possible to have certain beliefs about false claims. Similarly, we can have uncertain beliefs about true claims. From tossing a coin, we can expect a fair probability in which head and tails have the same probability. But we cannot know for sure if the coin is biased or not until it lands. Similarly, is possible that even our best theories are wrong or partially wrong. Even after many successful experiments, they might be proved wrong (see 1.4.1). In fact, scientific hypotheses can rarely if ever be proved right, they can, however, be proven wrong.
“We never are definitely right, we can only be sure we are wrong” — Richard Feynman
Below you can find a clip from the last lecture of a series of 7 special Messenger Lectures given by the renowned American theoretical physicist Richard Phillips Feynman. The transcription can also be found online.
While is relatively easy to determine cases of failed justification, is much harder to identify what suffices to justify a belief. Few claims can be conclusively proven so that no doubt remains. An ideal justification of a belief would consider all relevant reasons for and against believing a statement. This is why science is a human enterprise where justifications, hypotheses and experiments are made public for review, replication or rebuttal.
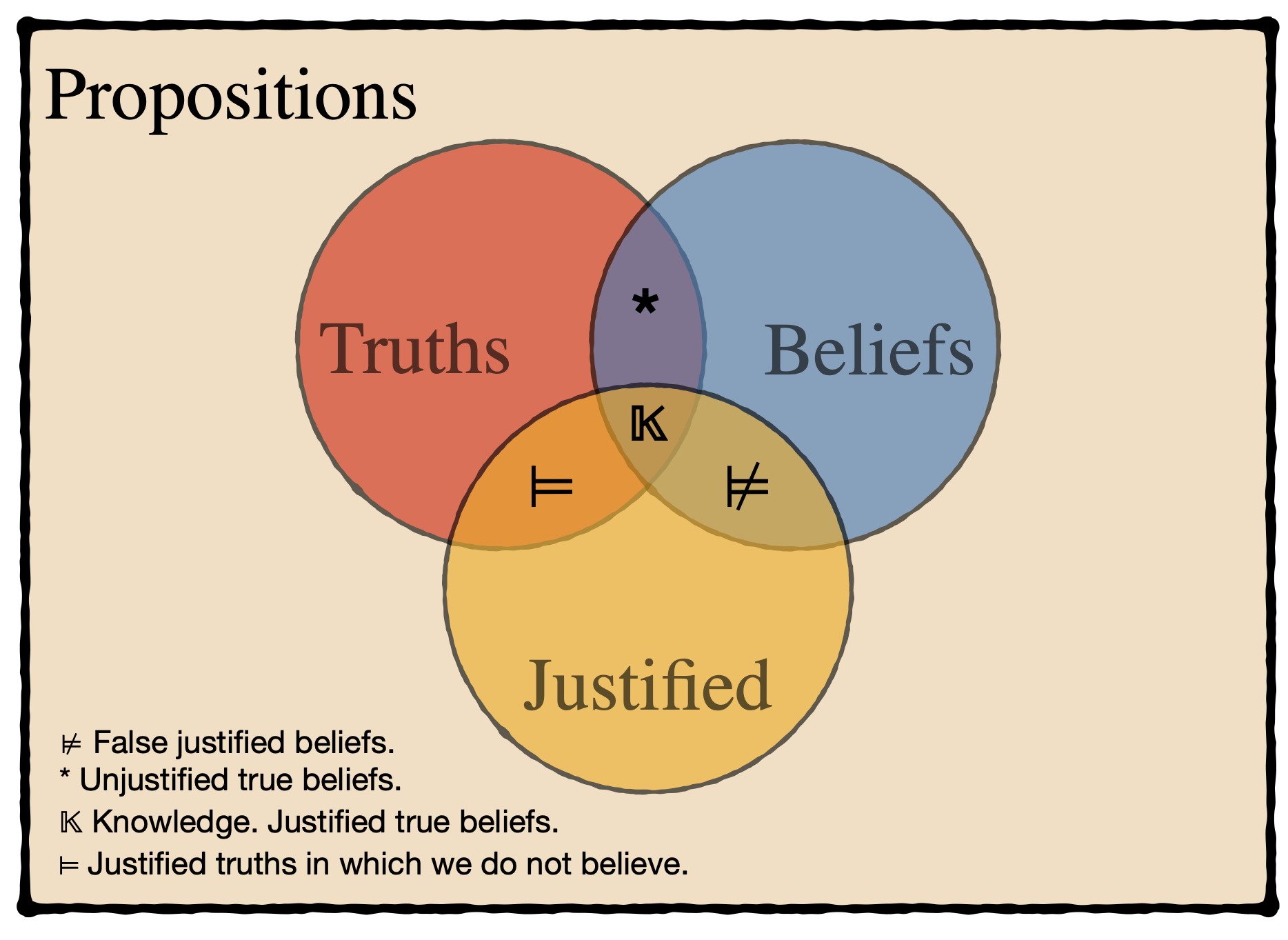
Figure 1.2: A Venn diagram illustrating the classical theory of knowledge.
Definitions should not be accepted without reason, and instead, we should attend to the arguments that support such definitions. Certain definitions may have widespread popularity but that doesn’t make them any more true. For example, a dolphin is a mammal even if many people consider it a fish. In the same way, tomatoes and cucumbers are fruits for botanists even if we daily sort them as vegetables. And sometimes, even the EU and the Supreme Court of the United States of America need to act to set certain market debates.
As another example, the first astronomers who lacked the telescope believed on the geocentric model because their observations did not suffice to reject it. These first astronomers had false justified beliefs. After the advent of the telescope in 1609, the geocentric model was rejected. But how do we know we are not in a similar situation that of the pre-telescope astronomers? Events as recent as the Michelson-Morley (see 1.4.2) experiment, the expeditions of Sir Arthur S. Eddington or the predictions of Urbain Le Verrier (see 1.4.1) have changed our conceptions of the universe and physics forcing scientists to re-formulate models and theories.
In the next chapter we will see how knowledge is obtained.
One [fundamental question of philosophy of science] is ‘how can we have knowledge as opposed to mere belief or opinion?’, and one very general answer to it is ‘follow the scientific method’. […] The branch of philosophy that inquires into knowledge and justification is called epistemology. The central questions of epistemology include: what is knowledge as opposed to mere belief?; can we be sure that we have any knowledge?; what things do we in fact know?. — (Ladyman 2012)
1.1.1.1 Data, information and knowledge
Nowadays, technology allows us to collect data into datasets, transform datasets into information and arrive at new knowledge. Such processes have always been crucial in science but computer science comes to question concepts such as data, information and knowledge. (Johansson et al. 2016)
By knowledge, we can understand three different things. First, knowledge of truths, e.g. we know that the sun rises on the east. Such knowledge can be obtained by reading a book or listening to the radio. The second category of knowledge consists of skills, such as riding a bike or speaking a foreign language. However, this knowledge requires more than language to be communicated. It requires practice. Finally, the third category is the knowledge of objects, what Bertrand Russell called knowledge by acquaintance (Russell 1912). This knowledge is obtained through experience.
In common English, we can’t distinguish between knowledge of truths and objects. However, languages such as German, French or Spanish make clear this distinction by using different verbs, Rusell proposed to use the word “acquaintance”.
- German: wissen vs kennen.
- French: savoir vs connaître.
- Spanish: saber vs conocer.
Example from William James (1890) — “I am acquainted with many people and things, which I know very little about, except their presence in the places where I have met them. I know the colour blue when I see it, and the flavour of a pear when I taste it; […]”
What is the difference between data and information?
The following excerpt from (Johansson et al. 2016) may clarify this question:
But why call the input ‘information’? The reason seems to be that we can describe the input as being about something, often the state of the environment. It has content. Or rather, when we humans describe the input and the workings of the system we find it natural to talk as if the information-containing system consciously sent messages to us humans; we say that the systems obtain information, transmit information or store information about something, as if it were like a human mind. The core feature of this use of the word ‘information’ is thus its aboutness, its intentionality.
Finally data. It is common in computer science to say that information is data with meaning. This is ok as far as it goes, but what is ‘meaning’? And how do data acquire meaning? It seems that minimally it means that meaningful data becomes information when we have been able to formulate declarative sentences expressing the information that is obtained from a data set. Almost anything can be data. In order to obtain data from e.g. a story, from light from distant stars, or from the result of an experiment, we need to divide the stream of sounds, lights, or states of detectors into distinct items. When using written text as data source one must divide the string of linguistic signs into distinct items, such as words or longer or shorter expressions. […] In short, in order to obtain a data set, we need to define a principle for dividing up something into distinct pieces. Hence from a conceptual point of view, discerning data and collecting a data set presupposes that we have a prior principle of making distinctions within a phenomenon. […] Sometimes we have lot of background knowledge from start.
In short, a piece of knowledge is a piece of information for which the knower can provide good reasons.
1.1.2 What is Philosophy of Science?
One of the tasks of philosophy of science is to question assumptions that scientists take for granted. For example, suppose a scientist conducts an experiment that yields a particular result. The scientist then repeats the experiment a couple of times more obtaining the same result. The scientist then stops repeating the experiment, convinced that repeating it under the same conditions will produce the same result. But why does the scientist assume that future repetitions will provide the same outcome? How are we sure this is true?
Therefore, one of the main objectives of philosophy of science is to study the methods and methodologies of enquiry used in the sciences, understanding how techniques like experimentation, observation and theory building enable scientists to reveal new knowledge. Philosophy of science asks questions such as: What is knowledge? What is a scientifically acceptable observation? What makes an explanation scientific? What is a scientific theory?
Finally, the philosophy of science tackles a wide range of topics that would require its own master. Moreover, not all topics are directly related to the aims of this course and the scope of the master. For this reason, a brief summary of the topics left behind is included in § 6. Of course, the curriculum is subject to change in the future and the list might change too.
It is usually thought that if there is anything of which science consists it is a method or set of methods, so the study of scientific method (known as methodology of science) is at the centre of the philosophy of science. — (Ladyman 2012)
1.2 The scientific method
The scientific method is the main pillar of science. All science begins with observation, as this is the first step of the scientific method. Moreover, such observation must be repeatable, either actually or potentially. Once an observation has been made, the second step involves the definition of a problem, or in other words, asking a question about the observation. However, such a question needs to be valuable scientifically, it must be relevant and must be testable. Questions need to be reformulated until they become testable. The third step may seem a rather unscientific procedure as it involves guessing what the answer to the question might be by postulating a hypothesis. The fourth step will tell the scientist if the hypothesis is correct through experimentation, which tests the validity of a scientific guess. Notwithstanding, experiments do not guarantee a scientific conclusion. Experiment results represent evidence, i.e. the hypothesis in answer to the question is confirmed as correct or invalidated. Given the latter, a new hypothesis with new experiments might be needed. Finally, experimental evidence is key for the fifth step of the scientific method, the formulation of a theory. A good theory has a predictive value, usually predicting that something is likely to happen with a certain degree of probability (Nidditch 1968).
1.3 Methodology
A method is a particular tool to reach a particular goal (e.g. statistical test). Methodology is the systematic assessment and justification of method choice. Scientists often need to choose between alternative methods in order to reach a particular scientific goal. But specifying a goal does not directly determine what method to choose. We need to consider the reasons why some method is better than another for a particular goal. This process could require a better definition of the initial goal or learning more about the context and domain where the methods will be applied. Methodology must be distinguished from describing methods, which usually concerns the design and implementation of particular research approaches and focus on the technical aspects (e.g. how to program simulations or set up instruments).
For example, a laboratory experiment can be advantageous because the test conditions can be controlled but laboratory experiments might not be realistic enough for certain tests. On the other hand, a field experiment provides more realistic test conditions but is difficult to control all variables.
Similar considerations may be necessary for other seemingly trivial questions such as model choice or data visualization. Should we use a significance test or a Bayesian approach? Should we present our results using a bar chart or a violin plot? Should we use a structural model or a quantum model? Methodology asks questions such as: What methods are available to reach a particular goal? What reasons speak for or against the alternatives? How should be weight the reasons to form a final decision?
How do we decide between alternative methods? Is there a way to determine what is rational to choose? Traditionally there are three ways to choose between alternative methods.
By convention, The methods are chosen because you have been taught to, or because is an established convention between your peers. Conventionalisms create long-term issues when methods become dominant in a field. A good example is the use of p-value in hypothesis significance testing. Similarly, accuracy and precision metrics in Machine Learning can be considered conventionalism. More problems arise when different disciplines have different conventions, hindering inter-disciplinary work.
Outcome-oriented. While choosing the method that yields the best results may seem well-intended and appropriate, this certainly sounds very vague too. The intention is to find a method that serves some purpose best, but this purpose is sometimes not sufficiently clear. Science frequently involves long-term projects where the final material outcome is uncertain or unknown. For example, the International Space Station or the Large Hadron Collider. This methodology raises the question of how to measure the outcome. For instance, is speed the best way to assess which car is best? Should we focus on fuel autonomy or pollution instead? What about combining all of them?
Reason-based. Choosing the method based on the overall best reasons seems the best option, particularly when the reasons include considerations that justify choosing a method over others for a given scientific goal (e.g. prediction). But sometimes there are methods that despite providing more valuable results could be unethical and/or illegal. For example, randomized control trials (RCT) are often employed to test the effectiveness of a new drug. Participants are divided at random into two groups (treatment and control), eliminating the effect of confounding factors on the outcome of interest. However, RCTs are not always feasible, for either practical or ethical reasons. For instance, it won’t be ethical to assign people to smoke for decades in order to study if cigarette smoking causes cancer. These other aspects need to be weighted together with the scientific reasons during method choice.
See 1.4.4 for an example of how reason-based methods are not always easy to implement while at the same time, outcome-oriented methods led the mainstream of an important debate.
1.4 Examples
1.4.1 Neptune and Vulcan
Newton’s gravitational theory predicted the paths the planets should follow as they orbit the sun. Most of these were confirmed by observation, but the orbit of Uranus differed from Newton’s predictions. In 1846 John Adams in England and Urbain Le Verrier in France solved the mystery. Both of them suggested that another planet, yet undiscovered, was the cause of an additional gravitational force exerted on Uranus. These scientists calculated the mass and position that this planet would need to have to explain Uranus’ orbit. The planet Neptune was indeed found close to the location predicted by Adams and Le Verrier.
So, instead of rejecting Newton’s theory right away (see 2.4.2), these scientists stuck to it and tried to find another missing factor that could explain the difference. When the motion of Uranus was found not to match the predictions of Newton’s laws, the theory “There are seven planets in the solar system” was rejected, and not Newton’s laws themselves.
However, Le Verrier also found irregularities in the motion of the planet Mercury and tried to explain them as resulting from the gravitational pull of an, again, yet undetected planet Vulcan. This hypothetical planet would have to be a very dense and small object between the sun and Mercury. In this case, no planet was found between Mercury and the sun. A satisfactory explanation was provided much later by the general theory of relativity, which justified irregularities through a new system of laws. In this case, the hypothesis or theory had to be reformulated or replaced by new one.
Below you can find a clip from lecture “The Law of Gravitation”, from the Messenger Lectures given by the renowned American theoretical physicist Richard Phillips Feynman.
1.4.2 The most famous “failed” experiment
The Michelson-Morley experiment (1887) was designed to detect the motion of the Earth through the luminiferous aether. XIX century physicists used aether to explain how light could be transmitted through empty space between the Sun and the Earth. The result of this experiment is considered to be the first strong evidence against the then-prevalent aether theory, and the beginning of a new line of research that eventually led to special relativity, which rules out a stationary aether.
To the ancients, the concept of a void universe was impossible. Aristotle arrived at the hypothesis of the aether to explain the cosmos and several natural phenomena such as the movement of the planets. By the XIX century, the aether became more than a philosophical need. Whenever there is a wave, something must be waving. But what waves when light waves travel from the Sun? For XIX physicists, the aether was the medium through which light waves from the Sun would propagate.
Michelson and Morley attempted to detect the absolute motion of Earth through space. For that, they set an experiment in which a beam of light was sent through a half-silvered mirror used to split the light beam into two beams travelling at right angles to one another. The beams were then reflected back to the half-silvered mirror by two respective mirrors and recombined into a single beam. The experiment can be seen as a race between two light beams. If the beams arrive in a tie, the result is a bright spot at the centre of the interference pattern, otherwise, a destructive interference would make the centre of the image dark. The hypothesis foretold that a tie was not possible since the two beams were racing on a moving track. It was assumed that the Earth was moving through the aether and therefore the beam should trace different paths with respect to the aether.
The extent to which the negative result of the Michelson–Morley experiment influenced Einstein is disputed. However, the null result helped the notion of the constancy of the speed of light gain acceptance in the physics community. This example shows the impact a well-designed experiment can have.
For a longer and deeper explanation of the experiment, its historical context and consequences, watch episode 41 from The Mechanical Universe. The timeline of luminiferous aether can be found at the Wikipedia.
1.4.3 Eddington expeditions

The following example also relates to falsification (see 2.4.2) which is taught in the next Chapter. However, this is also a good example of how a good theory should make definite predictions such as those from Einstein’s theory of general relativity.
Figure 1.4 shows the positions of different stars during the eclipse. Such stars are not normally visible in the daytime due to the brightness of the Sun but become visible during the moment when the Moon fully covers the solar disc. A difference in the observed position of the stars during the eclipse, compared to their normal position at night, indicates that the light from these stars had bent as it passed close to the Sun.
Einstein’s theory made a clear prediction: light rays from distant stars would be deflected by the gravitational field of the sun. Normally this effect would be impossible to observe — except during a solar eclipse. In 1919 the English astrophysicist Sir Arthur Eddington organized two expeditions to observe the solar eclipse of that year, one to Brazil and one to the island of Principe off the Atlantic coast of Africa, with the aim of testing Einstein’s prediction. The expeditions found that starlight was indeed deflected by the sun, by almost exactly the amount Einstein had predicted. Popper was very impressed by this. Einstein’s theory had made a definite, precise prediction, which was confirmed by observations. Had it turned out that starlight was not deflected by the sun, this would have shown that Einstein was wrong. So Einstein’s theory satisfies the criterion of falsifiability. — (Okasha 2016)

Figure 1.3: Instruments used in the 1919 observations to test Einstein’s predictions about warped spacetime. Credit: Getty Images
Einstein published his general theory of relativity in 1915. The total solar eclipse of 1919 offered the perfect opportunity to test it experimentally, by exploring whether — and how — the immense gravity of the Sun bends and distorts incoming light from more distant stars, as predicted by Einstein’s theory. For a brief moment during the eclipse, the Moon would block the Sun’s light in the sky and make visible some of the stars that lie close to the line of sight of the Sun, not normally visible during the daytime. By measuring the positions of these stars during the eclipse and comparing them to their positions at night, when the sun is not in the field of view, it would be possible to determine whether their light rays bends while passing close to the Sun. — European Southern Observatory

Figure 1.4: Eddington and Crommelin imaged the eclipse using the technology of the time: photographic plates made of glass. Sadly, the original plates from the 1919 expedition have been lost — but, luckily, copies of one of the plates were made and sent to observatories around the world to allow scientists everywhere to see the evidence in support of relativity with their own eyes. Source: European Southern Observatory.
One of the interesting facts from Stanley’s account is that Einstein had made a stab at calculating the bending of light back in 1911, before he had formulated the full general theory of relativity. His result was precisely the same as the Newtonian value. I was left wondering what would have happened to his reputation if measurements had been taken then. Would they have been a setback? Or would they just have driven him harder to produce the full theory, with its crucial factor of two? — (Coles 2019)
1.4.4 The smoke debate
In the mid-1700s, James Lind discovered that citrus fruits prevent scurvy, while in the mid-1800s, John Snow figured out that water contaminated with faecal matter caused cholera. These two examples share a common fortunate one-to-one relation between cause and effect. Deficiency of vitamin C is necessary to produce scurvy. Similarly, cholera bacillus is the only cause of cholera.
However, during the late 1950s and early 1960s, whether or not smoking caused lung cancer was not clear. The subject of the debate wasn’t tobacco or cancer but rather the word caused as one of the most important arguments against the smoking-cancer hypothesis was the possible existence of confounding factors that may cause lung cancer and nicotine dependency. Many smokers live long lives without getting lung cancer while others develop cancer without ever smoking. Plotting the rates of lung cancer and tobacco consumption makes the connection impossible to miss (See Figure 1.5). However, time-series data are poor evidence for causality. Researchers already knew about RCT though its use was unethical in this case.
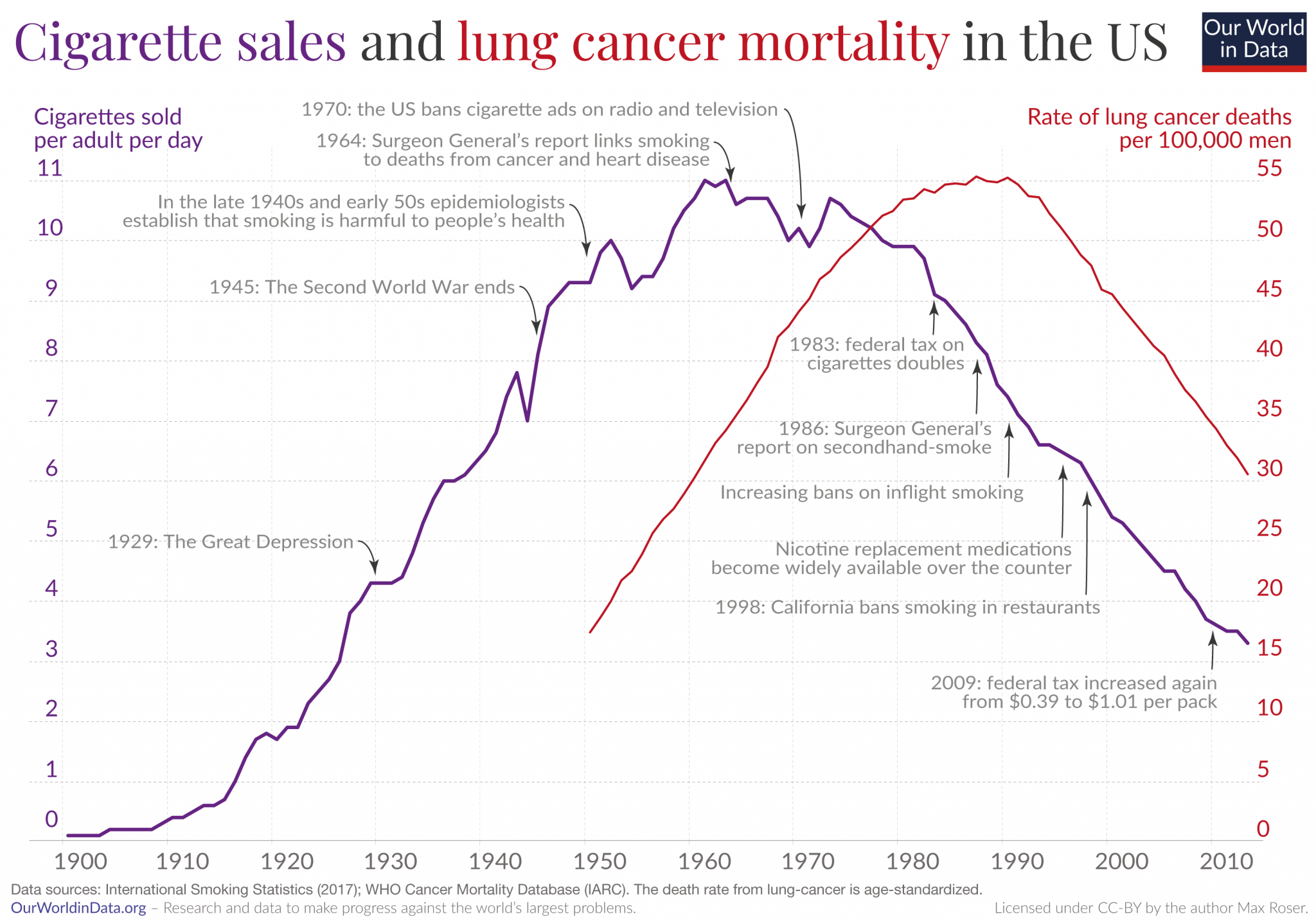
Figure 1.5: Source: Our World in Data.
Austin B. Hill proposed to compare patients already diagnosed with cancer to a control group of healthy volunteers. The results showed that all but two of the 649 lung cancer patients had been smokers. This type of study is today called a case-control study because it compares cases to controls. However, this method has some drawbacks too. First, the study is retrospective, meaning that participants known to have cancer are considered and researchers look back to understand why. Second, the probability logic is backwards, as the data tell us the probability that a cancer patient is a smoker instead of the probability that a smoker will get cancer. Moreover, case-control studies admit several possible sources of bias such as recall bias or selection bias. Hospitalised cancer patients were not a representative sample of the population, not even from the smoke population. Researchers were careful to call their results an “association”. Later on, the study was replicated with similar results. Deniers such as R. A. Fischer were right to point out that repeating a biased study doesn’t make it any better as is still biased.
We won’t focus on how this story ends here but is important to notice how methods chosen based on scientific reasons are sometimes tough to implement and often need to fight against outcome-oriented studies such as those sponsored by leading tobacco companies.
In the end, many subsequent studies settled the smoking-cancer debate. We will come back to this example in upcoming sections of the course. If you can’t wait, read Chapter 5 from the Book of Why, by Judea Pearl and Dana Mackenzie (Pearl and Mackenzie 2018).
1.4.5 Kekulé’s dream
The third step of the scientific method (see § 1.2) requires guessing an answer (or hypothesis) to a previously determined question. There is no clear method to arrive at a hypothesis. Experience, historical context, and previously failed hypothesis condition how a hypothesis is conceived. But sometimes hypotheses can be reached in the most unlikely and unconventional of ways. It makes no difference as long as the hypothesis is then scientifically tested before its acceptance. One of the most famous examples is the structural model of the benzene molecule. In 1865 the chemist August Kekulé hit on the hypothesis of the structure after dreaming of a snake trying to bite its tail (See Figure 1.6).
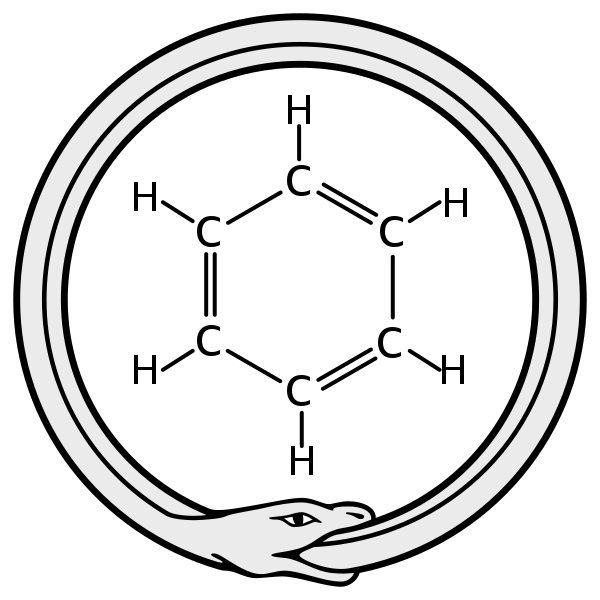
Figure 1.6: Source and credits to: Haltopub, from Wikimedia.
{kind=link}
1.4.6 Why Most Published Research Findings Are False
In his work Why Most Published Research Findings Are False, John P. A. Ioannidis (professor at the Stanford School of Medicine) argues that “the probability that a research claim is true may depend on study power (see note) and bias, the number of other studies on the same question, and, importantly, the ratio of true to no relationships among the relationships probed in each scientific field” (Ioannidis 2005).
In the form of corollaries, the author enumerates several factors making a paper with a positive result more likely to enter the literature and suppress negative-result papers. For instance, the popularity of a field or a trendy topic has more chances to have more publications about. Financial or political interests can act as prejudices affecting research and publication. Other factors such as sample size and effect sizes (e.g. the strength of the relationship between two variables in a population), experimenter bias, white hat bias (e.g. cherry picking the evidence and publication bias); flexibility in designs, definitions, outcomes, and analytical modes.
These corollaries consider each factor separately, but these factors often influence each other. For example, investigators working in fields where true effect sizes are perceived to be small may be more likely to perform large studies than investigators working in fields where true effect sizes are perceived to be large. — (Ioannidis 2005)
In summary, the problem is that researchers and institutions tend to value and promote “positive results” and discard negative results as not interesting to be published. This creates a bias in the scientific literature towards certain topics, designs and knowledge.
Thus, each team may prioritize on pursuing and disseminating its most impressive “positive” results. “Negative” results may become attractive for dissemination only if some other team has found a “positive” association on the same question. In that case, it may be attractive to refute a claim made in some prestigious journal. — (Ioannidis 2005)
Consider the following example provided by the author. Let \(R\) be the ratio of the number of “true relationships” to “no relationships” among those tested in the field. Let \(u\) be the proportion of probed analyses that would not have been “research findings”, but nevertheless end up presented and reported as such, because of bias. Importantly, “Bias should not be confused with chance variability that causes some findings to be false by chance even though the study design, data, analysis, and presentation are perfect. Bias can entail manipulation in the analysis or reporting of findings. Selective or distorted reporting is a typical form of such bias” (Ioannidis 2005).
Let us assume that a team of investigators performs a whole genome association study to test whether any of 100,000 gene polymorphisms are associated with susceptibility to schizophrenia. Based on what we know about the extent of heritability of the disease, it is reasonable to expect that probably around ten gene polymorphisms among those tested would be truly associated with schizophrenia, with relatively similar odds ratios around 1.3 for the ten or so polymorphisms and with a fairly similar power to identify any of them. Then \(R = 10/100,000 = 10^{−4}\), and the pre-study probability for any polymorphism to be associated with schizophrenia is also \(R/(R + 1) = 10^{−4}\). Let us also suppose that the study has 60% power to find an association with an odds ratio of 1.3 at \(\alpha = 0.05\). Then it can be estimated that if a statistically significant association is found with the \(p\)-value barely crossing the 0.05 threshold, the post-study probability that this is true increases about 12-fold compared with the pre-study probability, but it is still only \(12 × 10^{−4}\).
Now let us suppose that the investigators manipulate their design, analyses, and reporting so as to make more relationships cross the \(p = 0.05\) threshold even though this would not have been crossed with a perfectly adhered to design and analysis and with perfect comprehensive reporting of the results, strictly according to the original study plan. Such manipulation could be done, for example, with serendipitous inclusion or exclusion of certain patients or controls, post hoc subgroup analyses, investigation of genetic contrasts that were not originally specified, changes in the disease or control definitions, and various combinations of selective or distorted reporting of the results. Commercially available “data mining” packages actually are proud of their ability to yield statistically significant results through data dredging. In the presence of bias with \(u = 0.10\), the post-study probability that a research finding is true is only \(4.4 × 10^{−4}\). Furthermore, even in the absence of any bias, when ten independent research teams perform similar experiments around the world, if one of them finds a formally statistically significant association, the probability that the research finding is true is only. \(1.5 × 10^{-4}\), hardly any higher than the probability we had before any of this extensive research was undertaken! — (Ioannidis 2005)
Although most of the arguments and warnings of the paper are shared by most researchers, the work of Ioannidis is not exempt from critics. Researchers Steven Goodman and Sander Greenland published an analysis of Ioannidis’ approach (Goodman and Greenland 2007). Ironically, this latter work is much less cited that the original work. Goodman and Greenland agree on the conclusions and recommendations but reject the exaggerated language of the paper regarding the falsity of most published research. Researchers Jager and Leek criticized the model as being based on justifiable but arbitrary assumptions rather than empirical data. They calculated that the false positive rate in biomedical studies was estimated to be around 14% instead of over 50% as Ioannidis asserted (Jager and Leek 2014).
Whether the model is correct or not, Ioannidis’ claims are reasonable meta-scientific research continues to increase, providing stronger knowledge and more credible scientific literature.
Note for data scientists!
The study power is defined as “the ability of a study to detect an effect or association if one really exists in a wider population”. Clinical studies are conducted on a subset of the patient population because it is not possible to measure a characteristic in the entire population. Whenever a statistical inference is made from a sample, it is subject to some error. Researchers attempt to reduce systematic errors through proper design so that only random errors remain. There are two types of random errors to be considered before making inferences about the studied population: type I and type II errors. To make a statistical inference, 2 hypotheses must be set: the null hypothesis (there is no difference) and alternate hypothesis (there is a difference). The probability of reaching a statistically significant result if in truth there is no difference or of rejecting the null hypothesis when it should have been accepted is denoted as \(\alpha\), or the probability of type I error. It is similar to the false positive result of a clinical test. The probability of not detecting a minimum clinically important difference if in truth there is a difference or of accepting the null hypothesis when it should have been rejected is denoted as \(\beta\), or the probability of type II error. It is similar to the false negative result of a clinical test. Properly, researchers choose the size of \(\alpha\) and \(\beta\) before gathering data so that their choices cannot be influenced by study results. The typical value of \(\alpha\) is set at 0.05, and the significance level (\(p\) value) determined from the data is compared with \(\alpha\) to decide on statistical significance. The typical value of \(\beta\) is set at 0.2. The power of the study, its complement, is \(1-\beta\) and is commonly reported as a percentage. — Adapted from (Cadeddu et al. 2008)