HTTP Dissector
An HTTP dissector able to process traffic from PCAP files or straight from the interface at 10Gbps and more.
HTTPanalyzer
An HTTP dissector able to process traffic from PCAP files or straight from the interface at 10Gbps and more thanks to a technique which avoids the reassembly of the underlying TCP connection, matching the first packet of the HTTP request and the first packet of the HTTP response, disregarding the rest of the connection. Also, thanks to a new hash function (eq 2), we are able to match these 2 packets into a HTTP transaction, avoiding heavy hitter issues seen with traditional hash functions (eq 1). This HTTP dissector is been implemented in C language. The provided output format is the following:
client IP; client port; server IP; server port; request timestamp;
response timestamp; response time; response message; response code;
method; agent; host; URI
For example:
111.244.55.119|49713|132.124.34.218|80|1411039074.263069000|1411039074.300602000|0.037533000|OK|200|GET|example.com|/some/url/with/a/path/to/the/resource
This HTTP dissector is further described in the paper Multi-Gbps HTTP Traffic Analysis in Commodity Hardware Based on Local Knowledge of TCP Streams published in Computer Networks and available at arXiv. The paper is authored by Carlos Vega, Paula Roquero and Javier Aracil, from the HPCN research lab at Universidad Autónoma de Madrid. For the experiments described in the aforementioned paper, the revisited branch was used.
Cite as
Vega, C., Roquero, P., & Aracil, J. (2017). Multi-Gbps HTTP traffic analysis in commodity hardware based on local knowledge of TCP streams. Computer Networks, 113, 258-268.
Benchmark
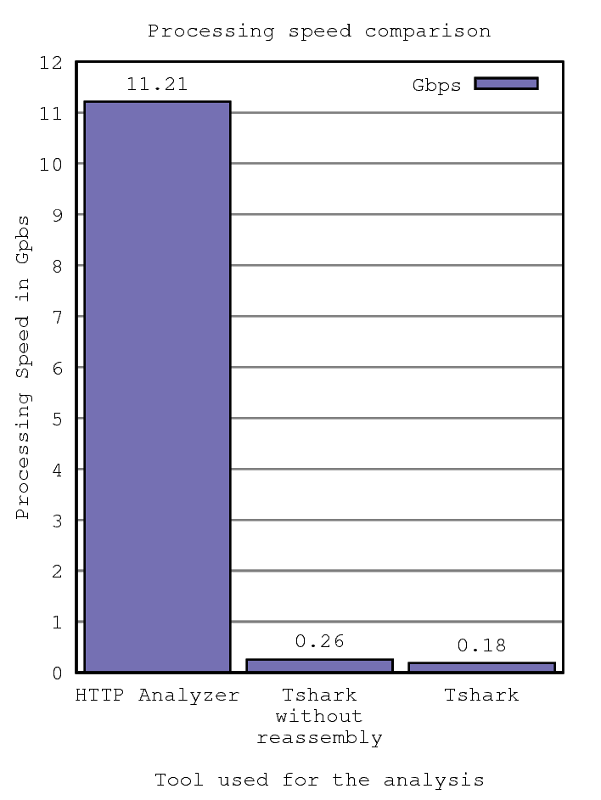
As seen in the next figure, the HTTPanalyzer is able to process traffic traces at speeds higher than 10Gbps. Of course tshark provides wider functionality and more powerful features targeted to packet inspection, which considerably affects its performance. This tool is aimed to high performance dissection in near real-time.
Hash for load distribution and memory organization
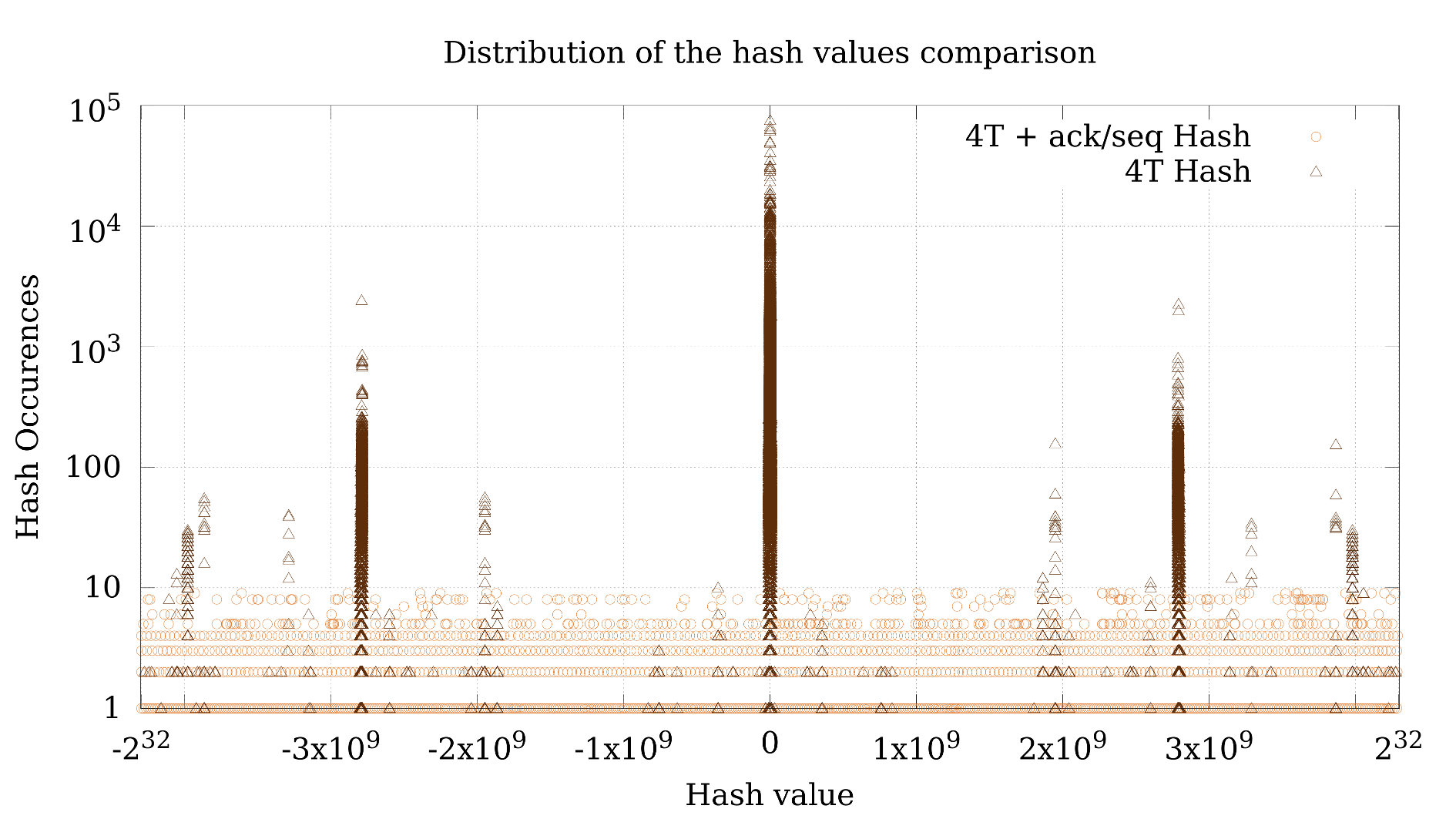
Instead of using the traditional hash function to distribute packets based on the connection information (source IP and port as well as destination IP and port), we add up the acknowledge and sequence numbers depending on whether the packet it’s a request or response, respectively. This technique avoids heavy hitter issues when some connections have more transactions or packets than others since it distributes the packets at transaction level instead of connection level, and uses the ack./seq. numbers which are randomly initialized during the connection initialization. The next figure shows a comparison of the distribution of the packets using different hash functions
Traditional hash function
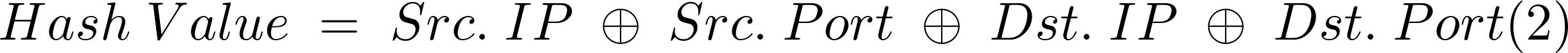
Proposed hash function
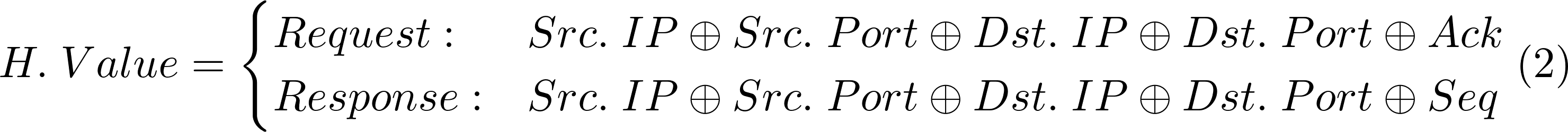
Modfied version of the proposed hash function for load distribution between consumers
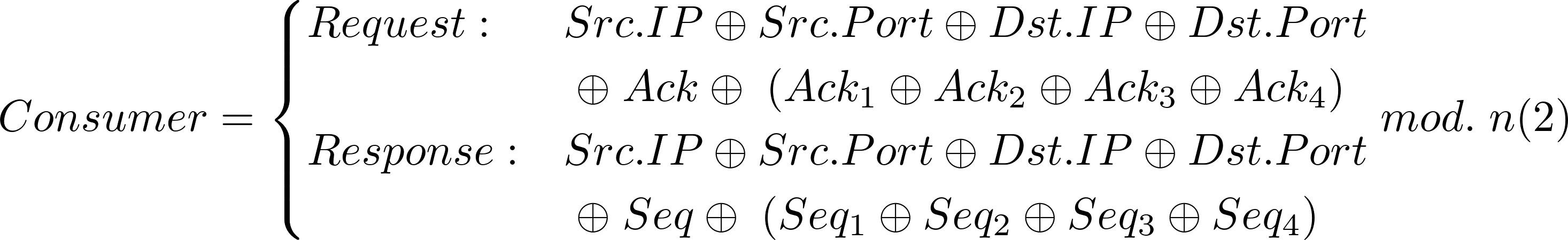
Limitations
The aforementioned procedure is not as precise as the complete reassembly of the TCP flows due to packet misordering and retransmissions.
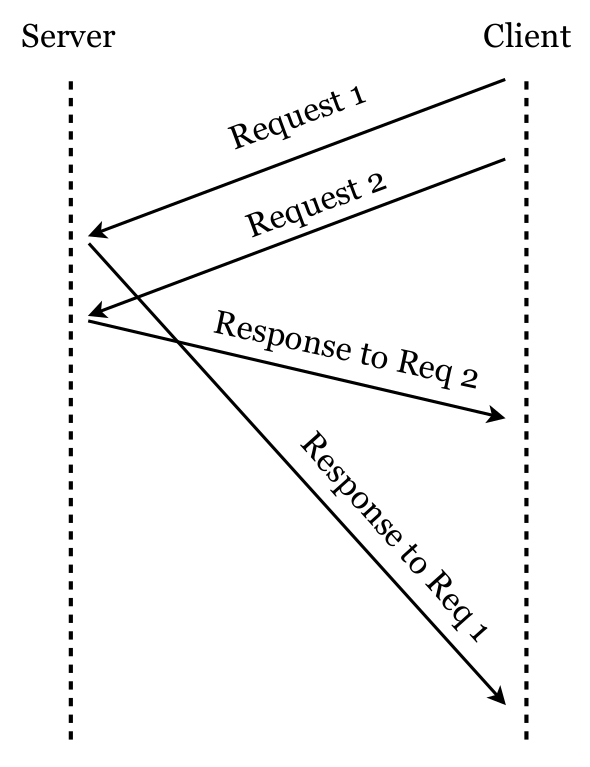
Unordered HTTP messages
To partially circumvent the issue with unordered HTTP messages we do store the HTTP message whether it is a request or response and keep it waiting to the counterpart, hence, pairing can happen in both orders.
Retransmitted messages
In the event of retransmitted messages, they are stored on their corresponding cell as well, in the collision list, resulting in duplicate transactions records. Such duplicate records must be filtered out afterwards by the analyst
Accuracy
As explained before, only the first packet of the request and response is considered in the evaluation of response time and response codes. Thus, the URL might be truncated if the packet is longer than the MTU (1,518 bytes). The RFC 2616 (Hypertext Transfer Protocol HTTP/1.1) section 3.2.1 says that “The HTTP protocol does not place any a priori limit on the length of a URI. Servers MUST be able to handle the URI of any resource they serve”